
A web content graph, part five; Information model design
A recurring thread running through the articles in this series is the information model. I have mentioned the use of classes, relations and metadata. Up to now, though, I haven’t covered how these come about. In this article I will address this and describe the design of the information models (or ontologies) that form the foundation for all of the other components. Here is what I've already covered and what to expect next.
- Guiding principles for content graphs
- Content design for content graphs
- Taxonomy design for content graphs
- Middleware design for linking information
- Information model design for content graphs (this article)
- Using a graph database to tie everything together
- Managing a graph database using the api
In this article
First steps in designing an information model ^
I like to think of an information model as a design for a digital twin representing a real-world thing. I always start by asking some questions about the real-world things themselves (by the way, using the word "thing" is not laziness; in the semantic world, everything is a thing one way or another, and semantic classes ultimately inherit from Thing).
- Is this thing something that I want to manage as an information object?
- Is this thing a more specific or narrower example of a more general thing? Can I re-use or inherit features from that thing?
- Is this thing a more generic or broader example of another thing? Can I construct a hierarchy of things?
- Are there other things that I can link to this thing?
- What information (metadata) do I want to capture to describe this thing? Can I determine the formats of these metadata items?
I'll describe how this process works in the case of the objects in my content graph.
Content architecture information model ^
In part 2 I introduced the content objects for our content graph. I selected content from the arXiv library (https://arxiv.org). arXiv is hosted by Cornell University, and to quote from the website,
arXiv is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
Here is a randomly chosen article from arXiv.

The information stored for an arXiv article is useful for our purposes here, as it seems well structured. For this article, the item for the RSS feed looks like this:
<item>
|
There is a title, author(s), an abstract (though not the full article content, note), an id, a link and a couple of other items of metadata. The designers have used intelligent design for the urls, so that the url for the pdf can be inferred from the url for the abstract, and both are based on the arXiv id. There is a two-level categorisation scheme that can essentially tag the article.
I decided that for this graph I would like to design Content graph items with these properties:
- URI
- Abstract (link)
- arXiv id (plain text)
- Author (plain text)
- Body (formatted text)
- ArXiv category and sub-category (plain text)
- PDF (link)
Leaving aside the process of getting this information into a content management system (I covered this in part 2), I had to think about how I would store and manage this information. For this I created a Drupal content type that would provide an appropriate location or slot for each type of information. This figure shows the definition that I developed for the Content graph article Drupal content type.
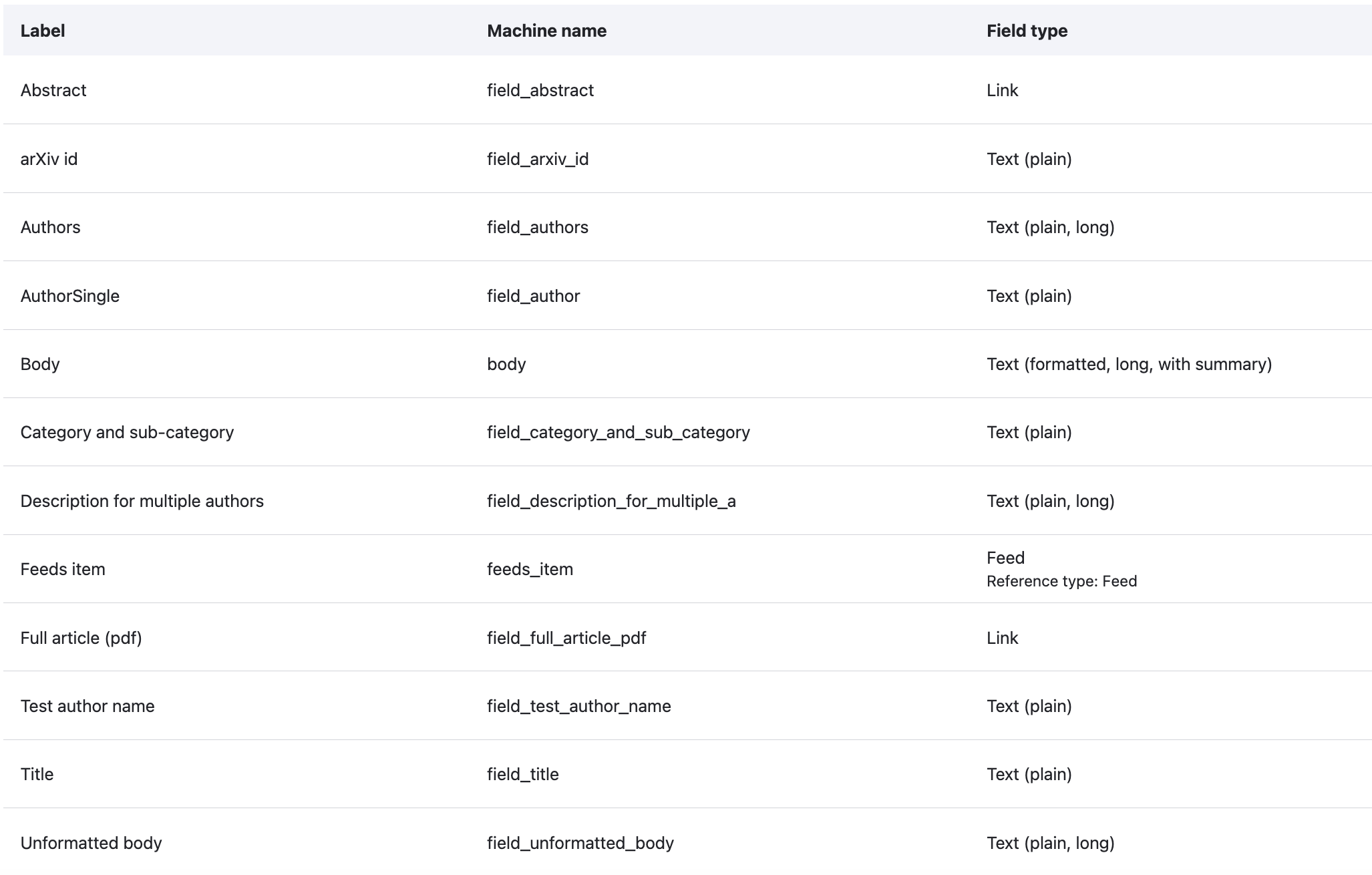
I'm not using all of these in the content graph. These are the important properties that I want to use, because I'm keeping it simple for this work.
- arXiv id (used to generate the URI of the Content graph item)
- URL of the arXiv article pdf
- Author name(s)
A note on the URI pattern ^
Note: my requirements changed over the course of this work. Initially I decided to use the automatically generated Drupal URI pattern, based on the Drupal node id (nid). This resulted in URIs like this:
http://maramotswe/CGM/web/node/29460
This is fine; it conforms to the rules for URIs and would have been usable in the content graph. However the URI pattern was not really meaningful, and was specific to my local network. Also, I decided that I would prefer to have more consistent URIs across the different parts of the content graph. So for Content graph items I decided to create URIs in this form:
https://content.tellurasemantics.com/content-graph/content-graph-item/[arXiv id]
This has the advantage of being meaningful, and it also uses the arXiv id, which is intended to be unique across the content library. I described in part 4 how I generated these URIs using Xojo code.
Content graph author content type ^
Turning to the Content graph author content type; my needs are simpler here. Because arXiv content does not contain author information in a structured form, there is not a great deal that I can do. A single arXiv page has an authors field that contains all of the authors in a single comma-separated string. I managed to separate out the individual authors using the comma-separation. However it was infeasible to further parse out the parts of the author name(s), because there was considerable variation in how author names are structured. A further complication is that in many cases the organisational affiliation for the author is also included in this field:

With sufficient effort it might be possible to parse out structured author information, this was not really needed for the current work. So I decided to live with the information I could extract, which is the combined author name (and possibly affiliation) information for a single author. This is far from satisfactory, but pragmatism was the driver here.
For URIs, I decided to generate values based on the consistent URI pattern described above, plus the Drupal nid (unlike the Content graph items, Content graph authors have no unique ids on the arXiv site).
https://content.tellurasemantics.com/content-graph/content-graph-author/[nid]
So for Content graph authors I could retrieve this information for a single author:
- URI
- Author name
Building the content architecture information model ^
I used PoolParty to create the content architecture information model. Using the PoolParty ontology tools is fairly straightforward; there are UI tools for creating models, classes, relations and attributes (attribute is the name PoolParty uses to describe data properties or metadata). As this is not a PoolParty tutorial I am not going fully to describe the steps for creating and populating a model. However, I will show some of the key steps. Here is the collection of relations for Content graph items and Content graph authors.
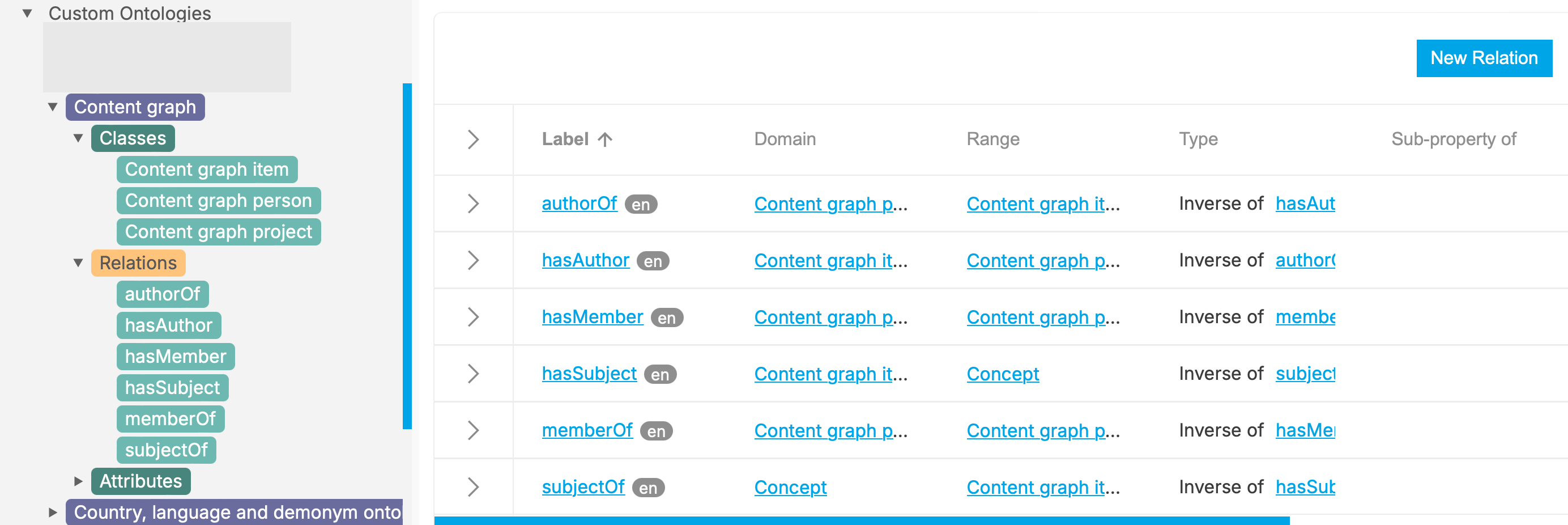
I've mentioned Project as a possible content class a few times, and in the figure above Content graph project is present as a class within the Content graph model. Suppose I wanted to create some relations linking projects with people and organisations. The most likely relations are:
- A person may be a member of a project. So I should create inverse relations for memberOf (domain of person, range of project) and hasMember (domain of project, range of person).
- A project may have one or more associated documents (say, a project report). In which case, I need to create inverse relations for hasProjectReport (domain Content graph project, range Content graph item) and projectReportFor (domain Content graph item, range Content graph project).
Let's create the project-person relations. To create a new relation, use the New relation button.

This dialog box is quite complex, and needs some explanation. In PoolParty, when you create a relation it may be one of several types:
- Directed. This is a one-way relation pointing from one class to another. I rarely use this type, as it does not lend itself well to building an extended or transitive network.
- Symmetrical. This is a relation between two objects where the relation is equal. For example, if you want to create a relation between two people who have the same parents, you might have hasSibling as a symmetric relation.
- Inverse. This is a relation in which the classes are complementary. If you have two siblings, you might have hasBrother as a relation with brotherOf as an inverse relation (by the way, the rules for this relation may refer to a domain of Brother or Sister, since either of these might have this relation with a brother as the range. Model design can be complicated!).
I'm creating an inverse relation here. I'm going to call the primary relation memberOf (a person is a member of a project). I'll set the domain as Content graph person.
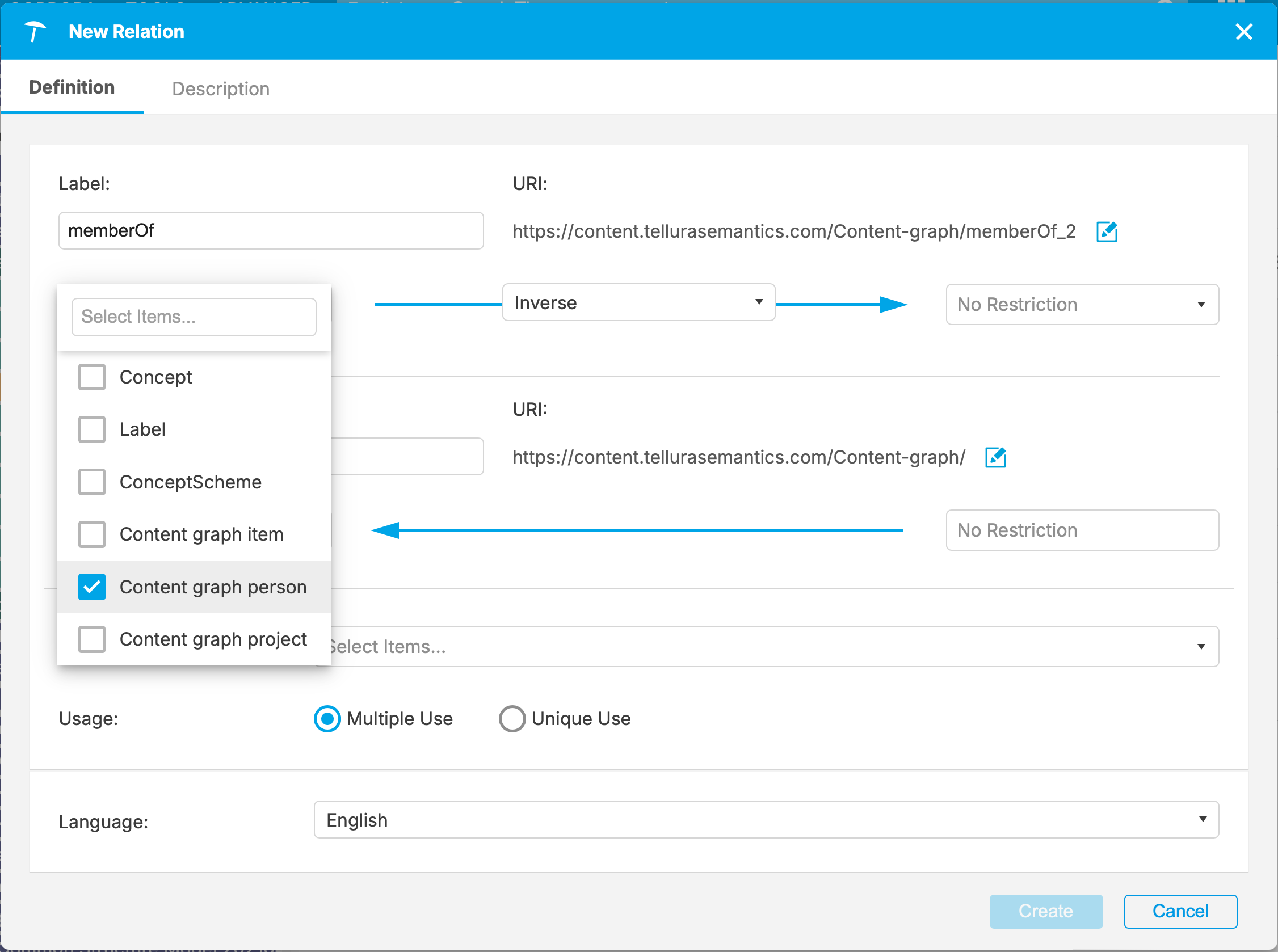
Notice that the URI has been created for me. Next I set the range for the relation (Content graph project).
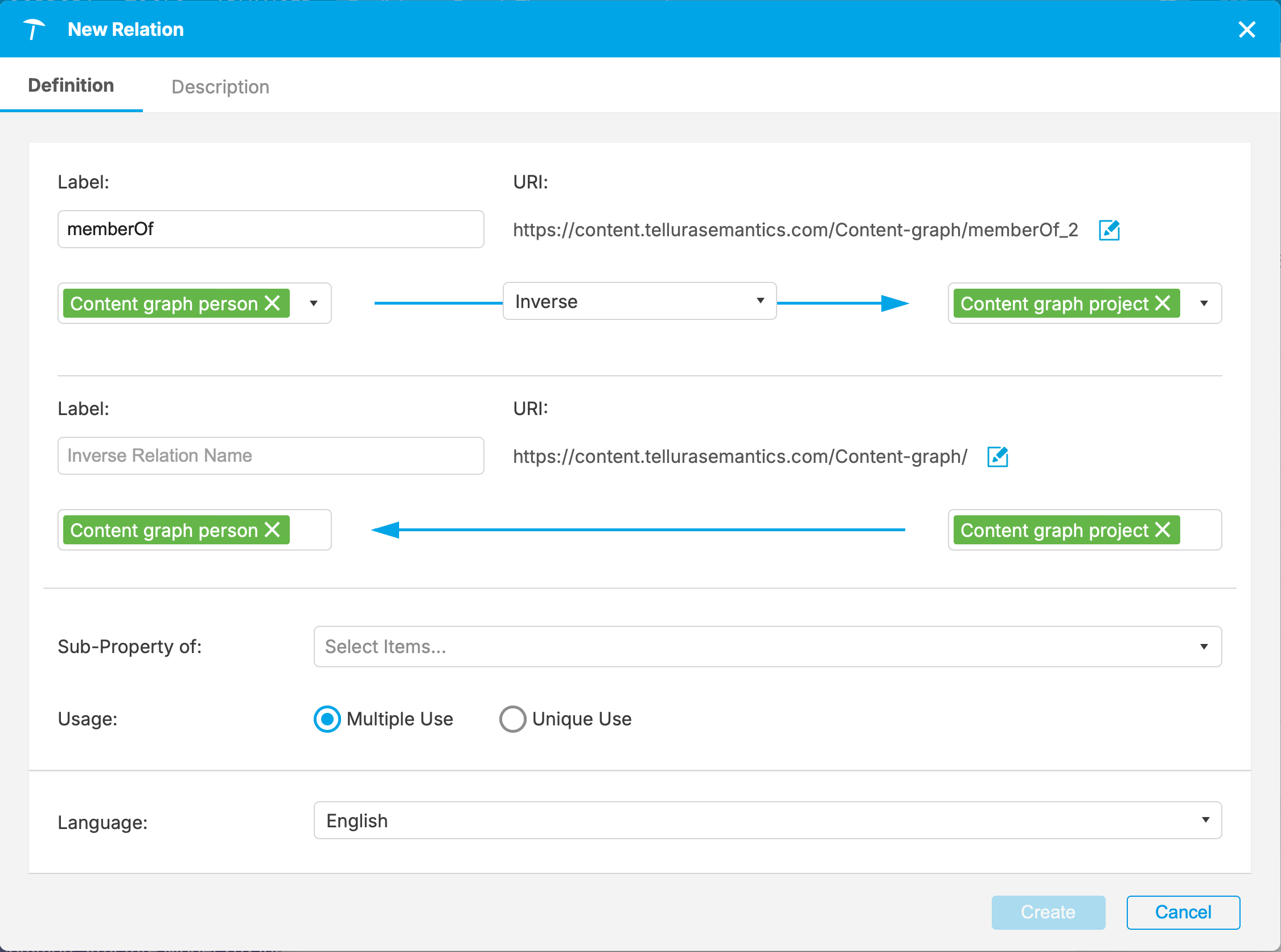
Now the inverse relation has been partially created. The green buttons indicate the two-way relations. The next step is to define the name of the inverse relation (hasMember):
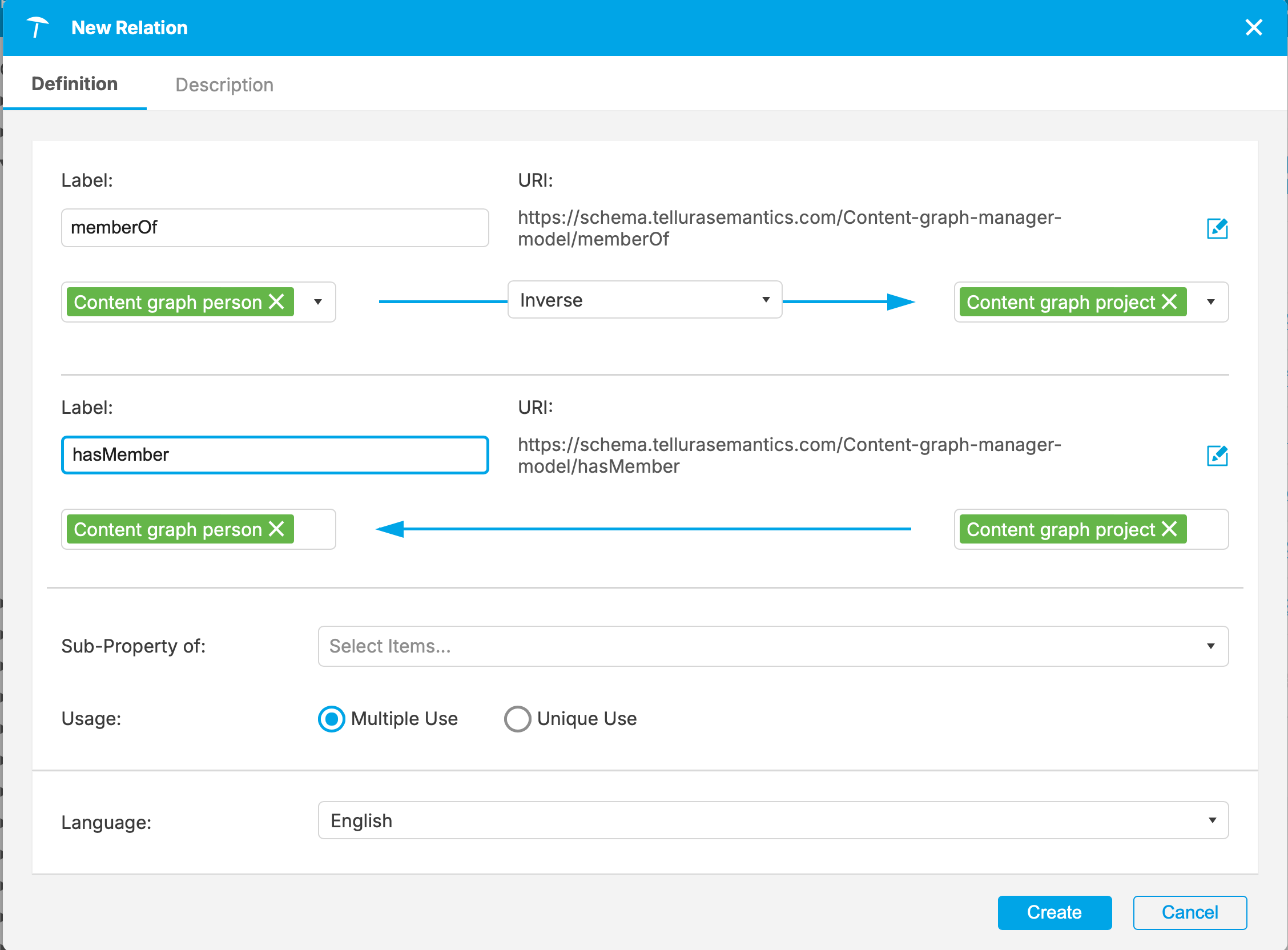
By default a relation is multi-use (it's possible to have multiple objects at each end of the relation), and I can make this relation a sub-property of another (but frankly I have never done this). There is another tab to allow a Description, which I have completed here.
Once completed, the two new inverse relations are in the list:
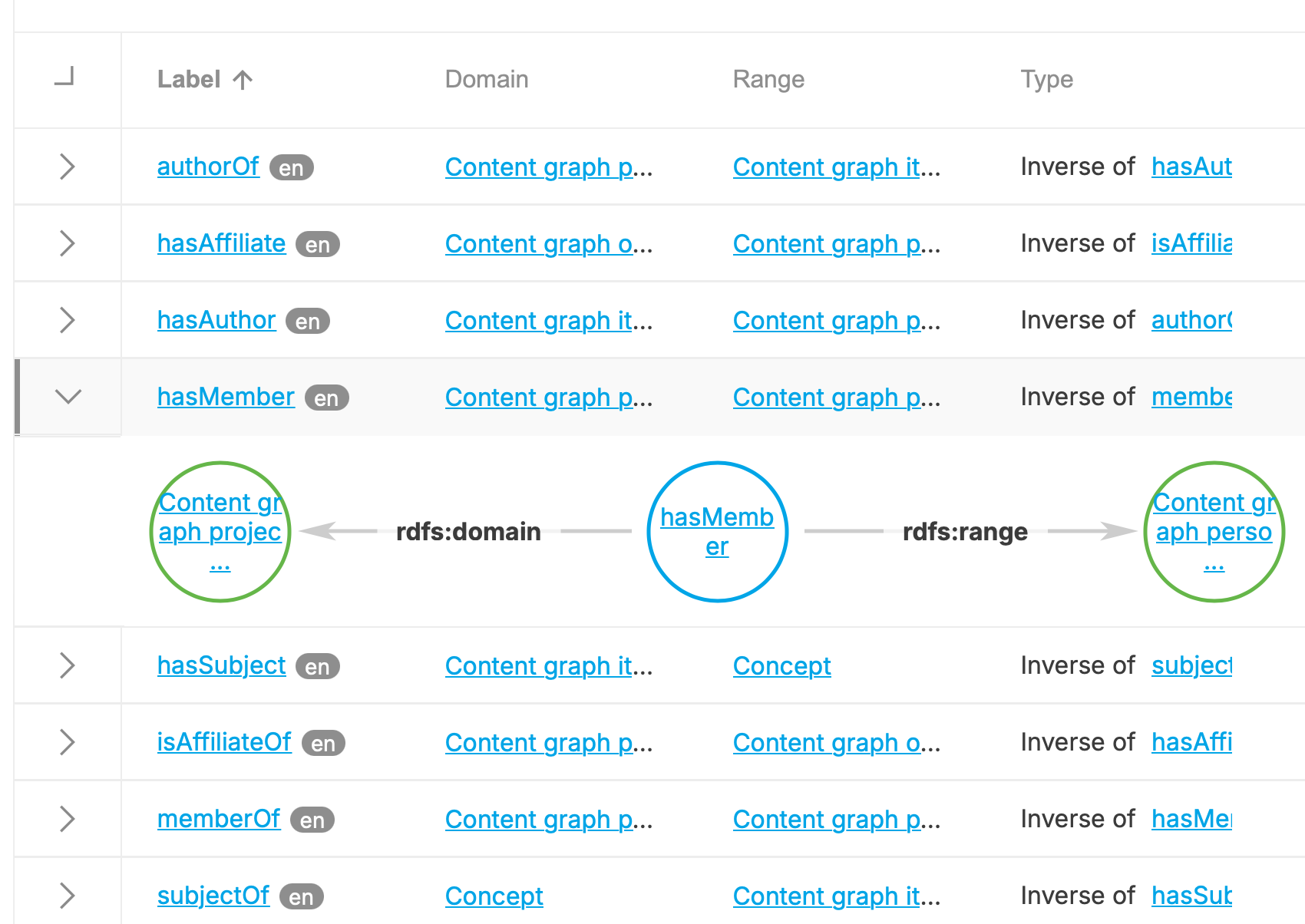
The model created here can be imported directly into any PoolParty project and optionally also exported to an RDF file for use in other applications. Here is how this model looks when exported in N-triples format (I've only included some of the triples):
<https://schema.tellurasemantics.com/Content-graph-manager-model/hasMember> <http://www.w3.org/2000/01/rdf-schema#domain> <https://schema.tellurasemantics.com/Content-graph-manager-model/Content-graph-project> .
<https://schema.tellurasemantics.com/Content-graph-manager-model/hasMember> <http://www.w3.org/2000/01/rdf-schema#range> <https://schema.tellurasemantics.com/Content-graph-manager-model/-Content-graph-person> .
<https://schema.tellurasemantics.com/Content-graph-manager-model/memberOf> <http://www.w3.org/2000/01/rdf-schema#domain> <https://schema.tellurasemantics.com/Content-graph-manager-model/-Content-graph-person> .
<https://schema.tellurasemantics.com/Content-graph-manager-model/memberOf> <http://www.w3.org/2000/01/rdf-schema#range> <https://schema.tellurasemantics.com/Content-graph-manager-model/Content-graph-project> .
I have highlighted the first triple in red. This triple defines the fact that hasMember has a domain of Content graph project. The N-triples format contains, on one line, a triple with subject, predicate and object URIs, and terminated with a dot (".").
Taxonomy information model ^
One pair of relations in the model manages the classification of content with concepts. This is the relations hasSubject - subjectOf. These describe how Content graph items are linked to taxonomy concepts.

The relation hasSubject has the Domain of Content graph item and the Range of Concept. Concept in this case refers to the taxonomy. In a SKOS taxonomy most of the objects are SKOS concepts (SKOS defines a few other classes but the most important one is Concept.

The SKOS Concepts in this taxonomy are all objects with the expected properties: URIs, relations and attributes. So these Concepts can comfortably co-exist with the other components of our content graph.
So the relation that we use in our (fairly simple) content graph is hasSubject - subjectOf. The model therefore is also quite simple; 4 classes, 8 relations and 6 attributes:

There really isn't a great deal more to say about this particular model. While this is a working example, in a real world case it is likely that the set of classes, relations and attributes would be considerably larger. However the principles of design that underly an information model like this would be exactly the same.
End of Part 5 ^
All but one of the main components of our content graph are now in place. I have a model that helps describe Content graph items, Content graph authors and taxonomy Concepts. I have instances of these types of content and built semantic middleware to extract and compare them, building a large network of linked data triples.
In the final part of this series of articles, I will talk about how this network of linked data triples can work with a graph database.