
Desktop content graph article 1. Building a content model for file linking and classification
The main topic for this article is how files in the file system need to behave when incorporated into a content model. The main purpose of the content model (or ontology) is to describe all of the class structure, object properties and data properties for the things that the information model contains. This will be a very simple content model with only a few classes, relations and other metadata to have to handle.
Given this content model it should be fairly clear what will be needed to build the same model in my Desktop content graph management system.
The starting point is not ideal
One of the biggest difficulties in this project is that I have to build the content graph outside the operating system and any content-handling application. I can’t (and wouldn’t want to) subvert the way that MacOS and (say) Microsoft Word work or the interfaces that they expose. Actually, that’s a shame; wouldn’t it be nice if the OS managed file system objects as objects? Wouldn’t it be nice if Word had an API that allowed external services to interact with documents?
We are where we are, and as a consequence building a content graph requires building a semantic layer over the file system objects, and implementing the graph design in that layer.
Modelling the real world
Where do you start in building a content model? For me, the starting point is to think about the real world things whose behaviour needs to be modelled. Then describe them in plain English, considering ideas such as:
- Is this thing a more specific example of another thing (in information terms, a sub-class)?
- Is it a more general example of another thing (a superclass)?
- Is it similar, or related, to another thing?
- If so, describe the relationship in terms of its type (define the semantics; these are object properties in the ontology)
- How would the thing be described in terms of its features; name, synonyms, relevant dates and times, and so on (these are data properties in ontology terms, or more generally, metadata)?
A model described in this way is occasionally called a digital twin; that is, an information structure that represents (as far as possible) the real world thing.
In this case we are talking about things in the file system; files and folders. And actually I’m only going to deal with file objects; a folder (sometimes called a directory) is really just a virtual container, an organisation system for files, so let’s stick with the truly definable objects.
Modelling files
Given the questions above, how should I characterise a file object?
Is a file a more general or more specific example of another thing? No, for these purposes a file is the only object we need to deal with. Even where a software program allows for structured objects (e.g. Word allows composite documents with a master and child documents) these have to be handled within the software. The operating system and the file system don’t keep track of those relationships. More specifically, when you move a file from one location in the file system to another in the same file system, most of the properties of the file (file name, size, creation and modification dates, inode; basically, the ones reported when you use the stat command) don’t change. The exception is the nativePath property; since that describes the folder structure leading from the file up to the top of the file system, it will change when the file moves, even within the file system. However, we don’t need to worry about nativePath since it’s not really a file property.
Is it similar to another thing? Absolutely; that’s the core of what I’m doing here. We all know that there are files that are similar to other files. The current Mac OS however does not provide ways to objectively define relationships between files. Since we don’t have those tools, we have to think of how to model the relationships that we want to build, then build those tools and do so outside of the files themselves or any current software tools that manage files.
Regarding metadata, files already have some of these provided by the operating system (filename, file size, created and modified dates, etc.), and they are quite accessible.
Uniform Resource Identifiers (URIs)
A core feature of objects in a graph-based ontology is that they have Uniform Resource Identifiers (URIs), which are unique, immutable identifiers and locators. And that is a problem when working with file objects, because there is no concept of a URI or even a GUID (Globally Unique identifier) in the main operating systems.
Since they are foundational for graph models, for this information model I am going to need URIs for my file objects. For a discursion into URIs, I’ve written a short section here.
Let’s just review where we are with the model.
- The initial objects that the model knows about are files. There is no hierarchy of files, since I’m not dealing with folders.
- Files may be related to other files. To begin with I’m just going to have a generic isRelatedTo relationship. This will be a symmetrical relationship; if file A has this relationship to file B, then file B must have the same relationship back to file A. The model may develop sophisticated relationships as the requirements develop, and the corresponding semantics will also develop.
- There are some clear data properties that can fit into the model. These are mostly normal file properties provided by the operating system
- A little later on I will introduce taxonomy concepts into the model. These are absolutely essential components, since they form the semantic glue that will hold objects together.
Building a model in Protégé
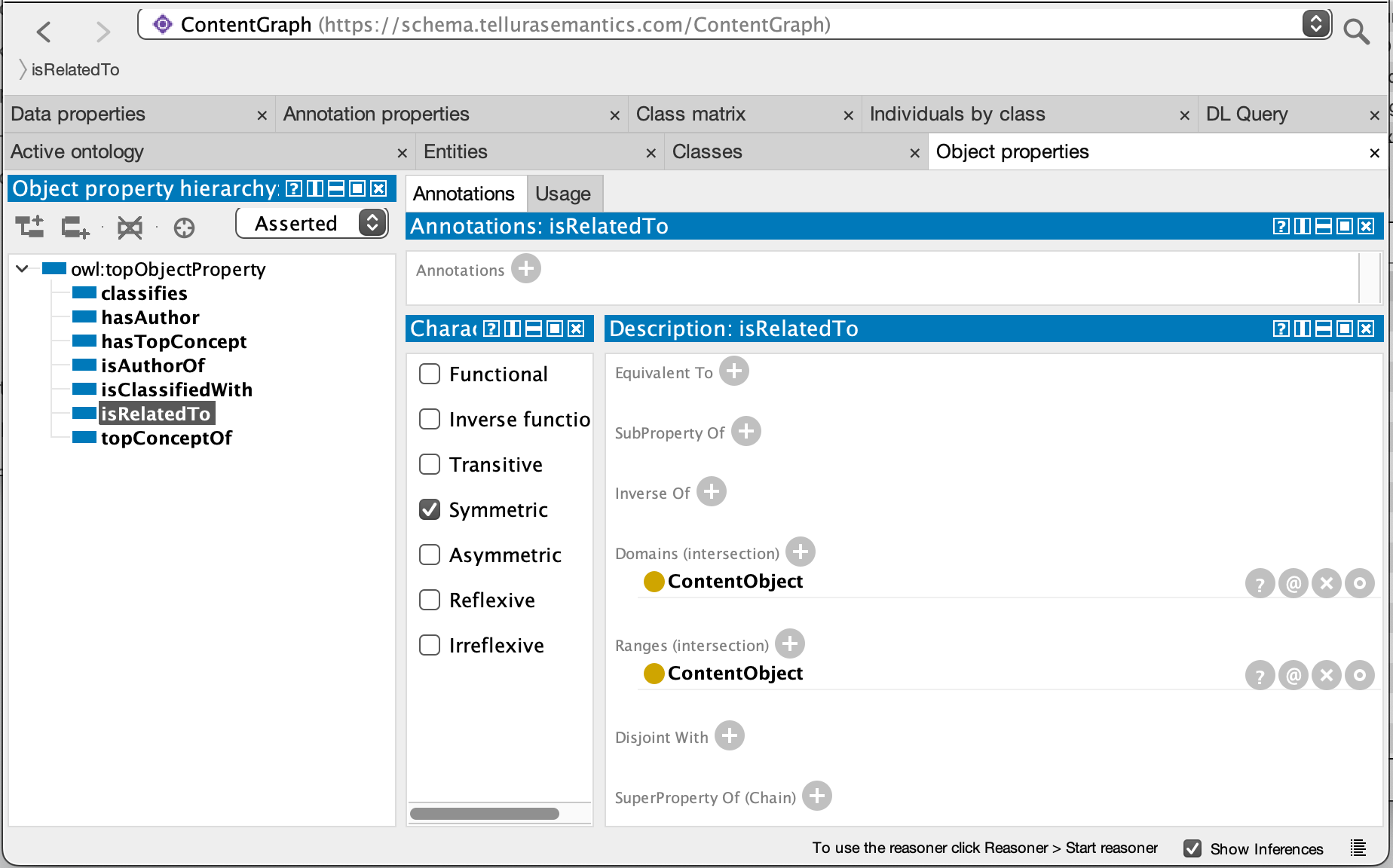
I use the free software tool Protégé to build graph models. The UI is a little quirky but once over the learning curve it is a productive tool. Since this is not a book about Protégé I’m not going to describe the whole process, but the screenshot below is a typical view for the desktop content model in Protégé. This shows the object properties view, and the highlighted property is isRelatedTo. The domain and range for this property are both ContentObject (this is the top level class that defines an item of content). The property is shown as Symmetric (so it applies in both directions).
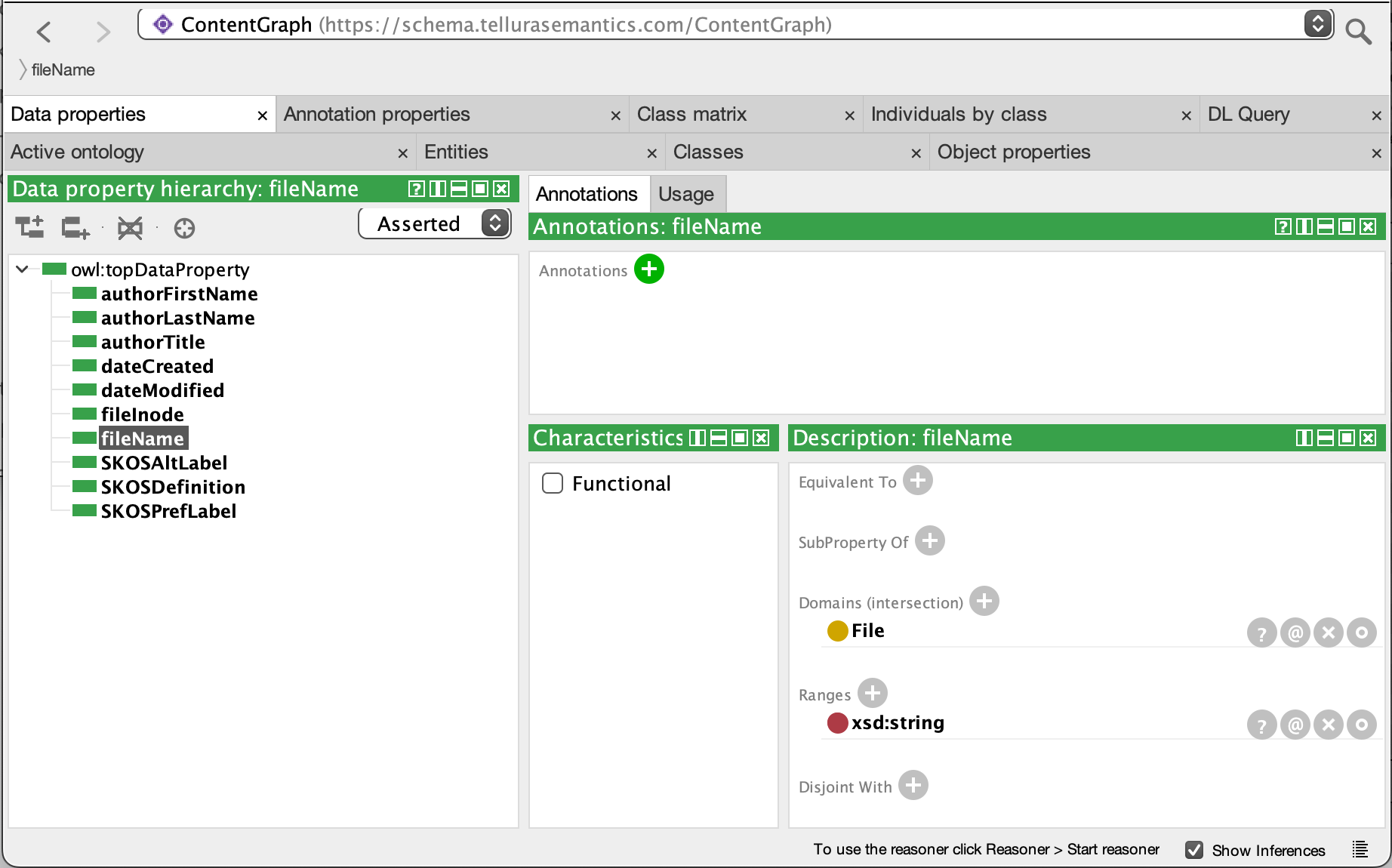
The data properties look like this. In the image below the highlighted property is fileName, which is a string property of a file.
Without going any further into the Protégé aspects, the model that I developed looks like this:
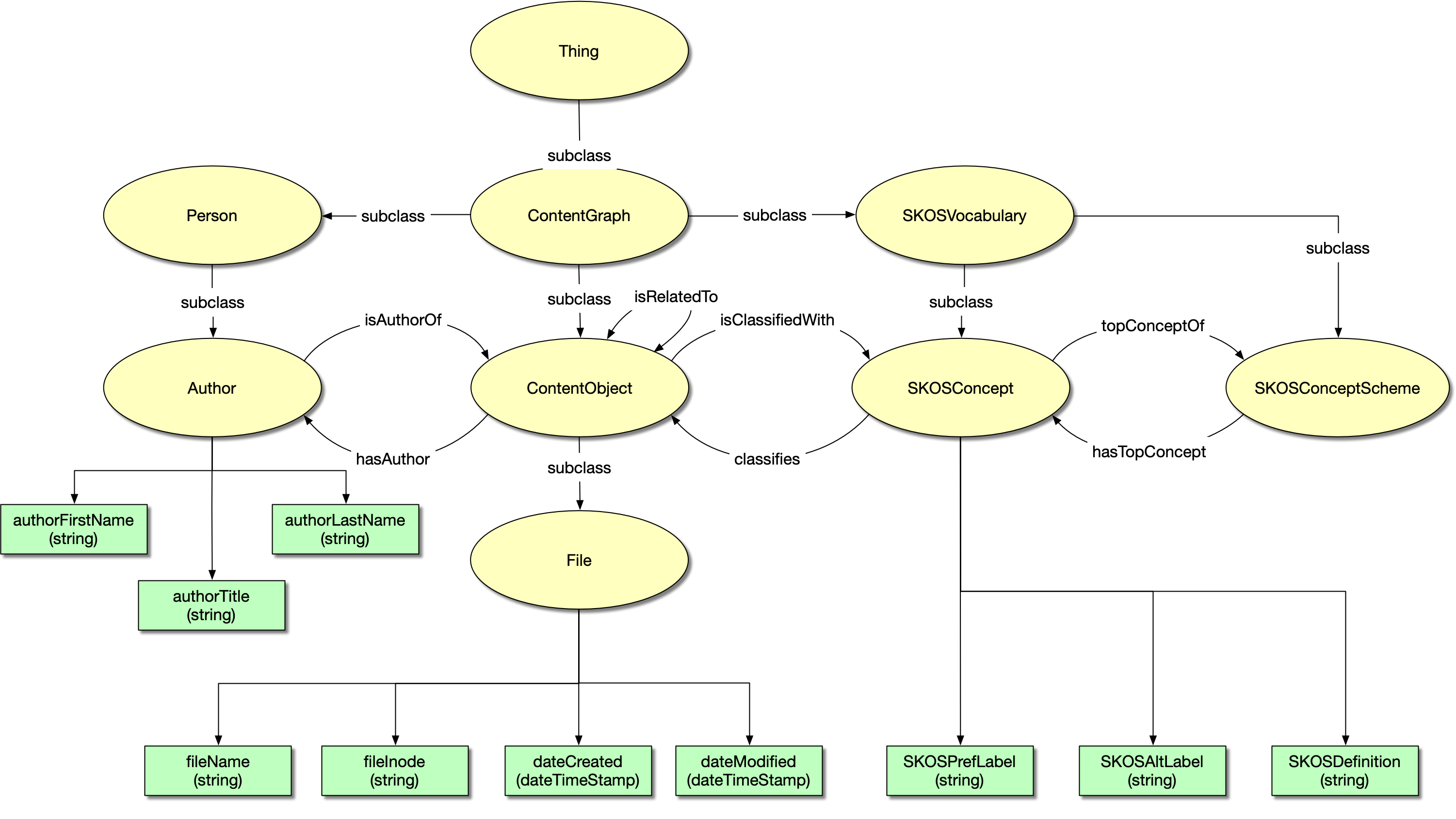
This needs some explanation. The image above shows classes (yellow ovals), object properties (labelled links) and data properties (green rectangles).
Classes
- Thing is the top level class in the model. All classes eventually can trace their parentage up to Thing.
- ContentGraph is a sub-class of Thing, and the top class in the content graph hierarchy. All of the classes I’m working with descend from ContentGraph.
- ContentObject is a sub-class of ContentGraph. Any thing that manages content will descend from ContentObject.
- File is a sub-class of ContentObject. I’m distinguishing between the two because File deals specifically with file system file objects, while ContentObject could manage other content objects that are not files.
- Person is a sub-class of ContentGraph. Any thing that is to do with a person will descend from Person.
- Author is a sub-class of Person, because the graph could contain persons who are not authors. However, an author (even in the days of AI-generated “content”) is a person.
- SKOSVocabulary is a sub-class of ContentGraph. It is the top level class of SKOS-related classes in this model.
- SKOSConcept is a sub-class of SKOSVocabulary. It is the main class used in classification of ContentObjects.
- SKOSConceptScheme is a sub-class of SKOSVocabulary. In RDF terms, a SKOS ConceptScheme is a virtual container for a SKOS vocabulary. Note that SKOSConcept and SKOSConceptScheme are disjoint classes. This might seem odd; you might think that a SKOSConcept should be a sub-class of SKOSConceptScheme. But in the RDF definition of the SKOS ontology they are separate and disjoint, so that’s how I am treating them here. I am not using SKOSConceptScheme in this current piece of work; it is there for completeness of design.
Object properties
- isRelatedTo has a domain and range of ContentObject. It is a symmetric property, so if ContentObject A is related to ContentObject B then B also has the same relation back to A.
- hasAuthor has a domain of ContentObject and a domain of Author. It is an inverse property together with isAuthorOf, which has the inverse domain and range.
- classifies has a domain of SKOSConcept and a range of ContentObject. That is, a SKOS concept is able to classify a content object. It is an inverse property together with isClassifiedWith, which has a domain of ContentObject and a range of SKOSConcept.
- The object properties for skos:broader, skos:narrower and skos:related are not part of the model design, because the taxonomy in use is flat (no hierarchy) and has no need for thesaurus capabilities.
- topConceptOf and hasTopConcept is an inverse relation linking SKOSConcept with SKOSConceptScheme. It is used in taxonomy development to identify the special case of a concept that sits immediately below (in virtual terms; no class hierarchy is intended) the concept scheme. I am not using it in the current iteration of this work. That may change in future.
Data properties
- fileName is a xsd:string property of the File class. It is used to hold the file name of the file.
- fileNativePath is a xsd:string property of the File class. It holds the fully qualified path in the file system to the file.
- fileOSOwner is a xsd:string property of File, used to contain the operating system owner name.
- fileOSGroup is a xsd:string property of File, and contains the operating system group name.
- fileInode is a xsd:string property of the File class. It contains the inode value. It is used in the current project to provide additional entropy in URI generation.
- fileCreationDateTime is a xsd:dateTimeStamp property of the File class.
- fileModificationDateTime is a xsd:dateTimeStamp property of the File class.
- authorFirstName, authorLastName and authorTitle are xsd:string properties of the Author class.
- SKOSPrefLabel, SKOSAltLabel and SKOSDefinition are xsd:string properties of the SKOSConcept class. When used for classifying File objects, the Finder tag will be converted into a SKOSConcept object and the text of the tag will become the SKOSPrefLabel.
- tripleSubjectURI holds the URI of the file that was defined as the subject for the triple. It is of type xsd:anyURI.
- tripleObjectURI holds the URI of the file defined as the object for the triple. It is of type xsd:anyURI.
- triplePredicateURI holds the URI of the file defined as the predicate for the triple. It is of type xsd:anyURI.
This basic model could be (and may be in future) developed further, but for initial design and build purposes this is enough.
In the next article I will begin to build the Desktop content graph model system.