
Desktop content graph article 2. Building the application
The conceptual design for a new application is in place. I’ve also developed the information model to a usable state. Now it’s time to start trying out a few ideas in code.
My starting point was to think about how I wanted the user to interact with the system. I’m a big fan of user-centred and visually-driven software and also drag-and-drop interfaces, so this was the starting point. Some of the requirements appeared quickly.
- The application needs to be independent of the operating system, so it needs to include a workspace where the user can place file objects and link them together.
- The user needs to be able to drag any file (or folder) in from the file system (the Finder, in the case of MacOS), drop it into the workspace and move it around as required. That is, the visual design should allow for drop, display and move of graphical objects.
- When a file is dropped into the workspace, the properties needed in the information model should be captured from the file and stored as object or data properties in the graph.
- There should be a clear and simple mechanism to link files together. When linking files the link type (or predicate) will be captured into the graph.
- There should be a facility to collect tag links. If a file dropped in the workspace has Finder tags then the application should create isClassifiedWith and classifies triples. This will be linked to SKOS Concepts derived from the tag string, with classification metadata using the information model. I would like to give the user the option to add further tags as SKOS Concepts.
- The workspace should show linked files. It could also display classification metadata (perhaps with a display toggle).
- The content graph will need to be saved out of the application. If the user has access to a graph database such as GraphDB, then there will be an export mechanism using the GraphDB API to send the collected triples to the repository. If the user cannot, (or chooses not), to use a graph database then the system can serialise the graph data out in JSON format. The mechanism that I’ve used here allows for de-serialising (round-tripping) the graph data.
Development environment
For the application design and build itself, I used a cross-platform development tool called Xojo. This is cross-platform both in the sense of being available in MacOS, Windows and Linux versions, and in the sense of creating native applications for MacOS, Windows, IOS and Linux. As I am not a development professional this flexibility is very appealing to me; the easier it is to get things done, the better. Xojo scores highly here; it has a clear user interface and a good code editor, and uses event-driven mechanisms widely. Of course, that would be of little use if it wasn’t also a highly effective tool. In fact I haven’t yet found any application area that I can’t work on with Xojo. Xojo comes with a good range of built-in controls and classes, but there is also a very well-established eco-system of plug-in controls, classes and modules that enhance the capabilities of the product. All in all, Xojo is a fully-featured professional object oriented development tool. As someone who has written a book on MacOS development with Xcode (an earlier iteration of Apple's Swift development tool) I can say confidently that Xojo is a far more productive design and build environment for applications.
So my approach to the program began with exploring how to manage graphical objects within the user interface. Xojo provides a built-in control called Canvas for this purpose; basically a workspace in which objects can be drawn, moved and resized.
I should probably mention at this point that I am not going to describe each stage of the development in tedious detail. Few readers would be that interested in that, particularly as my development strategies would best be described as disorganised. Instead, I will talk about the strategic approach, and show how the application works at particular stages. I will also include all of the code as an appendix. Xojo code is pretty readable; it has its roots in the beginner’s language BASIC, and in fact an earlier iteration of Xojo was called REALBasic (it has come a very long way since then, so any developer sniffiness about BASIC is quite misplaced).
Object design
In terms of object design, the program is framed around classes called Node, Link, Triple and TripleStore.
- A Node is an object that has been added to the workspace. It represents a file in the file system.
- A Link is the link between two Nodes.
- A Triple is the collection of two Nodes and a Link.
- A TripleStore is a collection of Triples
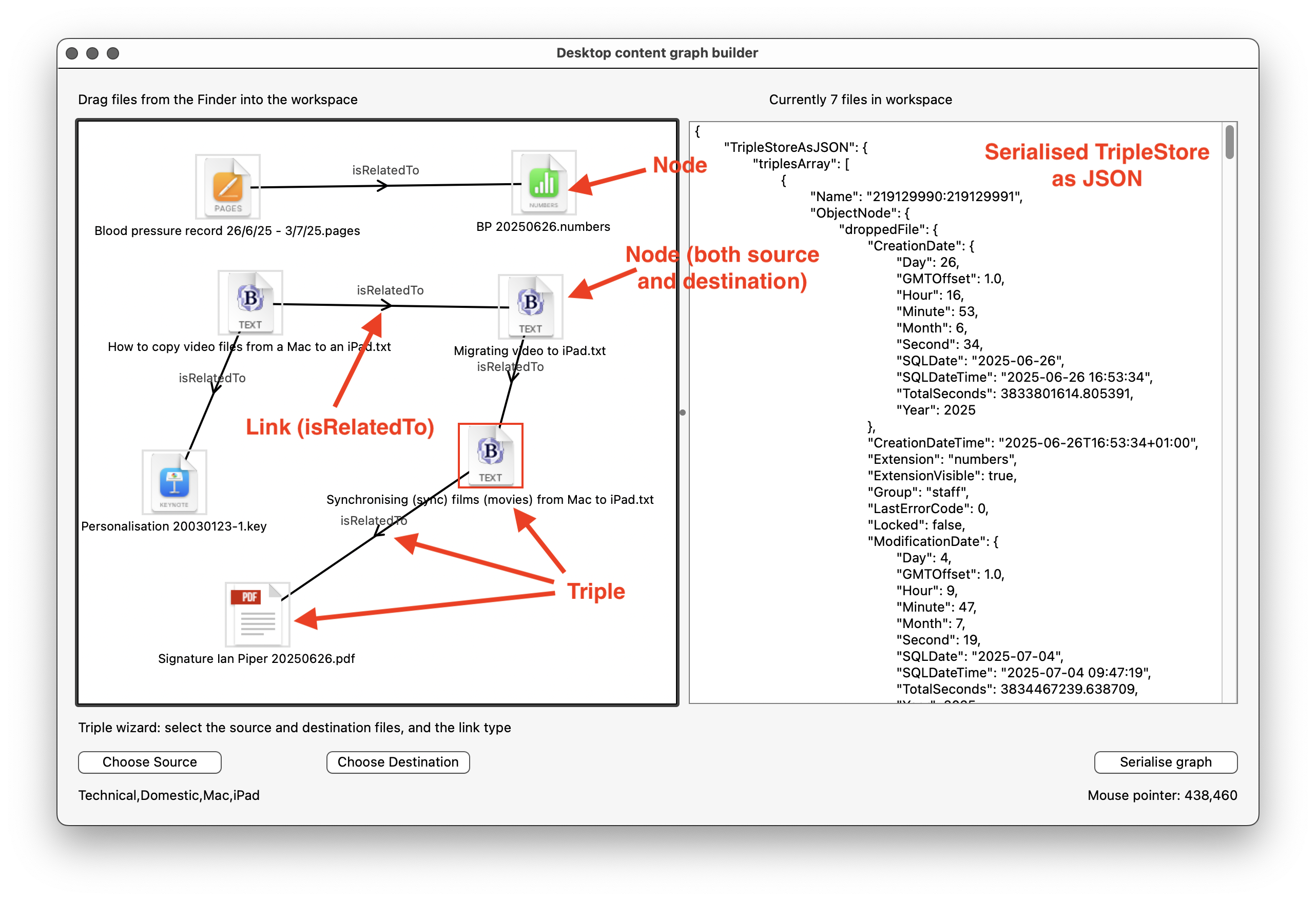
The image below shows the UI at the first stage of development. It shows a number of file objects that have been dragged into the workspace to make Nodes, and a set of links (as Link objects) between these objects. There are a number of Triples, where two Nodes are connected by a Link. The panel to the right shows a serialised form of the final TripleStore, which is a collection of triples. In the JSON document the root is called TripleStoreAsJSON, with a child of triplesArray, and a child from that of ObjectNode, which in turn has a range of metadata. Through this serialisation the same set of Nodes, Links and Triples can be restored later.
Some code talk
In this section I’m just going to introduce the Xojo approach to coding, with a couple of examples to exemplify it.
First, what happens in the code when I drag a file from the Finder and drop it onto the workspace?
Xojo is an event-driven tool, which means that controls are able to respond to an event. I’m not going into Xojo Events in massive detail, by the way, out of consideration for the reader. But a Xojo Event is triggered when something happens to a control (like dropping a file from outside the program onto it) and the Event handler deals with the result.
Xojo is also highly visual, allowing the developer to draw the user interface and to place controls within it. In the user interface I have built a Window object, and within that there is a Canvas. In the image above the Window takes up the main part of the image, and the Canvas is the area to the left with a heavy border. To the right of that is a TextArea, which holds multi-line blocks of text (that's just there for information purposes during the early stages of development by the way).
Over the course of the program I will be creating objects belonging to the Node, Link, Triple and TripleStore classes. Xojo is a fully object-oriented development system, allowing you design classes with their own sub-classes, events, methods and properties.
As the names suggest, a Node is the thing that I place on the workspace by dropping a file. It has properties such as x and y positions, object dimensions, FolderItem details, a URI, and other metadata.
Let’s look at Node in more detail.
This class exists to manage objects dropped on the workspace, so needs to have the appropriate methods, properties (and where appropriate, events). Here is how it looks in the Xojo application UI:
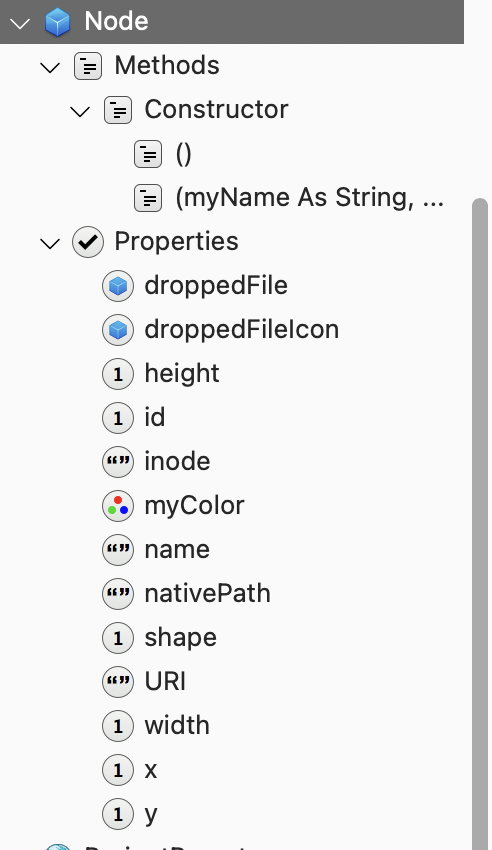
The Node class has a special method called a Constructor, a method that is run when an object is created (or instantiated). This is a way to create a new object complete with its properties. Actually, you can have more than one Constructor, with different sets of parameters, and in this case there is an empty Constructor. Without going into details, the reason for this is that I am using a plugin that will later on be used to serialise all of the necessary classes, and that plugin demands that each class has an empty Constructor. I have no idea why this is required, but it doesn’t cause me any problems to include it, so here it is.
The properties manage all of the necessary metadata for the Node, and should pretty self-explanatory. Suffice to say that once created, these properties enable the application to keep track of where it is, how big it is, what kind of thing it is, what colour is used for its border when it’s selected, and what file properties it has.
When a user does a MouseDown on a file in a Finder window, then drags it over and drops it on the Canvas within the application UI, it triggers a DropObject event on the Canvas, creating a new Node. Here’s how the code for DropObject looks. I’ve left out some of the details, but the entire code listing will be available at the end of this article.
First, the dropped object is picked up as a FolderItem (in Xojo, a FolderItem handles files and folders) and assigned to the file property of the Canvas. From this point I can manage it as an object called file. In the first line, I’m creating a URI (fileURI) for the new dropped file. I’m concatenating the native path of the file with the file inode, then running it through a custom method called generateURI.
Next, I’m creating a new Node object and adding it to an array called Nodes() (the parentheses confirm that it is an array of objects).
Next, I capture the list of Finder tags belonging to the dropped file, and put it in the Window status bar.
The final step is to redraw the UI using the Refresh command. The True parameter forces an immediate redraw (otherwise it will only happen when the user moves the mouse over the canvas).
fileURI = winMain.generateURI(file.nativePath + file.MacNodeIDMBS.ToString)
Me.Nodes.Add(New Node(file.DisplayName, obj.DropLeft, obj.DropTop, obj.DropWidth,obj.DropHeight,2,Color.RGB(255,255,255), file, file.MacNodeIDMBS.ToString, file.NativePath, fileURI))
// Show the Finder tags in the status bar
dim names() as string = file.TagNamesMBS
winMain.lblStatus.text = String.FromArray(names,",")
// Show how many nodes there are in the workspace
winMain.lblNodesInformation.text = "Currently " + me.nodes.LastIndex.toString + " files in workspace"
// Redraw the UI
Refresh(True)
By the way, a keen observer will see that the code that builds the new Node seems excessively duplicative; I’m passing in the file display name, the file native path, the file inode and the file URI, as well as the file object itself. Strictly speaking I could have just passed in the file object, and extracted the other properties from the resulting Node as needed, but the extra data makes it convenient from a data management point of view.
This is just a snapshot of the code in the application; I’m painfully aware that a professional developer will probably look at my code with disdain, or worse. Never mind; it does what I need it to do, which is enough for now.
What’s missing?
In my Desktop content graph, I can create semantically linked file objects, and I can save the linked data out as a graph. But I don’t yet have the tags for files captured in any meaningful way. It’s not that I don’t have them at all; if you look at the screenshot above you can see that the currently selected Node (red border) has, displayed in the bottom left of the window, Finder tags called Technical, Domestic, Mac and iPad. I captured these along with the file. However, these are just keywords; strings of text. In order to use them in the content graph I need to convert these Finder tags into objects with URIs and any other necessary metadata. That will be in the next article.
I haven’t yet put in place the tools to write the graph out to a GraphDB repository. I don’t anticipate any major issues with doing this, having done it many times before. In a similar way I need to create the code to write out the graph to a file (in case the user doesn’t have access to a graph database) and to round-trip the data back in. I'll cover this in the next article too.
At the moment, the user adds files to the workspace by drag and drop, and the process for linking them is manual (and, frankly, a little clunky). I’m thinking about a more elegant way of doing both.
In summary, this has been a promising start, and enough for an initial article, but there is a long way to go. Should be fun.