
A web content graph, part two; Content design
In this article I’m going to go into how well-structured content architecture is important in the design of content graphs. I will discuss how information is brought into a content management system and how it is consumed by external applications. I’ll cover how this can lead to better insights into the value of content. Here is how this article fits in the flow of earlier and later articles:
- Guiding principles for content graphs
- Content design for content graphs (this article)
- Taxonomy design for content graphs
- Middleware design for linking information
- Information model design for content graphs
- Using a graph database to tie everything together
- Managing a graph database using the api
In this article
By contrast with Part 1, in this article I will be going into content architecture, and its implementation, in some technical detail. I will describe the choice of tools for content management and the interfaces by which data can flow between a content management system and other systems.
Content structure in the source content ^
An analysis of content architecture should really begin with a clear picture of the content itself. I’ll illustrate this using a content source that I will use extensively in these articles; the arXiv library (https://arxiv.org). arXiv is hosted by Cornell University, and to quote from the website,
arXiv is a free distribution service and an open-access archive for nearly 2.4 million scholarly articles in the fields of physics, mathematics, computer science, quantitative biology, quantitative finance, statistics, electrical engineering and systems science, and economics.
From a content architecture perspective, arXiv provides curated content across a range of subject areas, and is made up of articles that have a common structure. Note that I do not know how this content is stored internally. Actually I don't need to know; I'm only interested in consuming information that the site is prepared to deliver via its API or feeds. That is a key aspect of distributed information. Here is a randomly chosen article from arXiv.

The information stored for an arXiv article is useful for our purposes here, as it seems well structured. For this article, the item for the RSS feed looks like this:
<item> |
There is a title, author(s), an abstract (not the full article content, note), an id, a link and a couple of other items of metadata. The designers have used intelligent design for the urls, so that the url for the pdf can be inferred from the url for the abstract. There is a two-level categorisation scheme that can essentially tag the article.
arXiv also provides (for many articles) a pdf that gives a layout similar to print:

A reasonable question here is why didn’t I just interrogate the arXiv site directly in building my content graph, since it appears to be well-structured and has an API and an RSS feed? The answer is that I wanted to demonstrate how content structure itself is designed, and I could only do that by building it, since I have no internal view of the arXiv content. Another important consideration is that arXiv (for understandable reasons) places limits on the quantity and frequency of downloads of its materials. For the purposes of these articles I only needed to use a small sample of content (fewer than 1000 articles). So for these articles I used an RSS feed to populate my content management system, and as you will see later, the pdf data was useful in building a taxonomy corpus.
This is not meant to be an article on arXiv; the main aim for this work was to find a high quality source of content based on which I could demonstrate how to build a content graph. However, I would like to thank arXiv for use of its open access interoperability. All use of its API and RSS features were done in accordance with arXiv’s terms of use (https://info.arxiv.org/help/api/index.html).
Content types in a content management system ^
For the content component used in these articles I had to identify a suitable content management system. The requirements were:
- Content should be capable of structured storage.
- It should be possible to build bespoke content types.
- It should be open source.
- It should have an import mechanism to bulk load RSS (from arXiv).
- It should have an API so that content can be consumed by external applications.
My choice was Drupal v10. Drupal is an extremely popular open-source content management system, used to power websites, intranets and other web-based applications. Drupal 10 meets all of the requirements that I’ve listed here.
The inferred structure shown in the RSS feed also fits well with my idea of the content part of the information model that I want to build in Drupal. All of the right fields seem to be there.
Drupal has a fairly steep learning curve, and I’m not proposing to describe how to install, configure, or in general how to use it here. You will, I hope, take my word for it that once past that initial steep learning curve it is a very productive and easy to use system.
For our purposes, in this set of articles, I want to store content that has a content type which I’m going to call Content graph article with these properties (type of each in brackets):
- URI
- Abstract (link)
- arXiv id (plain text)
- Author (plain text)
- Body (formatted text)
- ArXiv category and sub-category (plain text)
- PDF (link)
Drupal provides tools for creating and editing content, but for our current needs we need a way to import a large number of articles into this content type in one go. One of the great features of Drupal is its extensibility through contributed modules. A module is a piece of code (again, open source, so it is capable of inspection and modification) that is designed to carry out a specific function. The Feeds module, once added to a Drupal installation, allows you to import structured information from RSS and Atom feeds, and other data sources such as CSV. To use Feeds, you need to define incoming information and then map it onto the Drupal content type where you want the information to go. Once again, I’m not going to show my working; the Feeds module is quite complex and unduly focusing on it here would be a distraction from the main purpose of building a content graph.
Importing Drupal content using Feeds ^
I used the Feeds module to import a collection of several hundred articles from arXiv into my Content graph article content type. Here is a screenshot of the Drupal item of one randomly selected article.

I used another Feed to import the authors of these articles into another content type called Content graph author. I won’t go into the detail here of how I did this either, as, in addition to the complexity of Feeds it was quite an involved process to parse out the individual author names from the comma-delimited field of author names in the original arXiv article. The Content graph author content items also contain links to the articles that they authored, as a URI based on the node id of the Content graph article item. You can see in the image below that Boris Shoikhet authored an article entitled Lifting formulas II, which I’ve stored as a Content graph article with a Drupal node id of 29341, resulting in a URI of http://maramotswe/CGM/web/node/29341 (you can't follow this link by the way). Notice that the affiliation for this author seems to be concatenated with the author name. I’ll talk a little more about this later.

However, it is important to stress that I am only using Drupal in this case as a repository of articles and of authors. At present I am not concerned with linking them together. That will happen later on when I develop the middleware. Instead, I am using the principle of separation of concerns (in short, each system should contain only the information it is designed to contain) to ensure that I use the content management system only as a content store for structured content.
By the way, don’t worry about the ugliness of these images; Drupal is being used here only as a content repository, and I have not applied any styling, hence the vanilla presentation. Later on, I can selectively extract the content using a RESTful API and present it however I wish.
So now I have a collection of Content graph articles and another collection of Content graph authors. Each conforms to its own specified content type which defines the structure of the content; what fields and what data type are in each field. Each has a globally unique id which is exposed as a Uniform Resource Identifier or URI. This is what I need to build the content graph.
Exporting Drupal content using Views ^
To make this information useful in my content graph I need to make it available in a structured form to other applications. To do this I use another contributed module; RESTful Web Services. Explaining how this works is, like Feeds, quite involved, but it needs explanation of some other Drupal concepts first in order to be clear about the benefits.
Within Drupal, single items of content are stored as information objects called nodes. Each node can be retrieved by its node id (nid in Drupalese), and in fact in these articles I’m using the node id as a way of storing the URI for author content.
When you want to create collections or lists of content objects in Drupal, the most common way to do it is via a View. A View is a template or recipe for dynamically aggregating content items that meet a set of criteria. It is a simple rules engine allowing you to pull together all of the things that meet your needs.
Views have many uses within Drupal, but the one we’re interested in here is that once you have a View showing a set of content objects, you can create different displays for that View. Typically, you use a display within a View to populate a list of content in a block of content on a web page, or to populate an entire page, but you can also choose to create a RESTful end point. This is a special link that, when followed, returns a list of matching content objects in a JSON package.
Let’s look at exactly how I did this for Content graph articles and Content graph authors.
First, let’s think about the information that we would want to retrieve about Content graph articles. The main properties are the article title, the URI (derived from the node id) and the authors. The image below shows how a View designed to deliver this information might look.
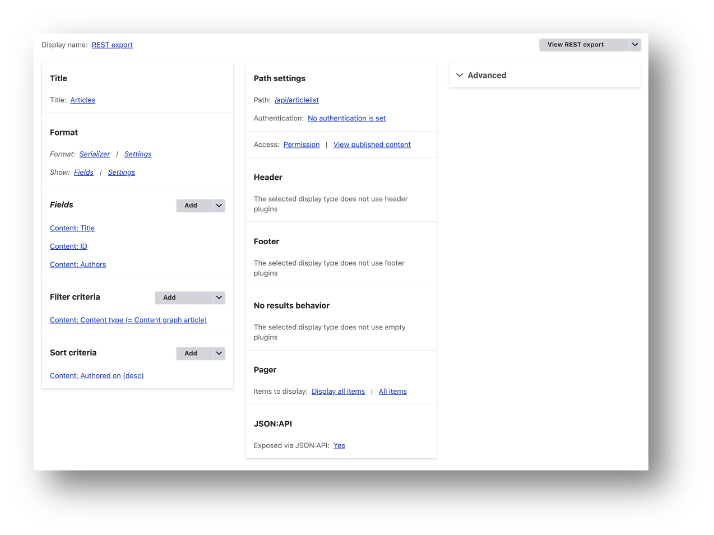
This is the View display for the RESTful export. Without going through every configuration setting, this shows that the relevant fields (article title, ID and related authors) are selected, with a filter based on just Content graph article content. The list is sorted by date. There is a defined RESTful endpoint (/api/articlelist). There is no pagination defined in the results, since this is designed to return a complete list of matching results (Views can have defined pagination if the display is a block or a page). One part that needs further explanation is where we specify that articles with multiple authors should have separate lines for each. This happens in the field configuration for Authors. In this section it is possible to specify that multiple values should appear in separate rows (see the highlighted field in the screenshot):

The result of this configuration can be seen by loading the corresponding uri for this view: http://maramotswe/CGM/web/api/articlelist (you can't follow this link either). Here is a short section of the JSON data.
|
Note that there are three JSON nodes, all referring to the same article, but with three separate authors. JSON is an excellent data structure to work with, and most software development systems include tools for processing JSON structures. My preferred product is a cross-platform development tool called Xojo (https://xojo.com). I will mention Xojo applications throughout these articles, and in a later article I will be going into a lot of detail describing the use of RESTful api methods in building the middleware component for the content graph.
For Content graph authors, the situation is similar. This content type allows us to store the name with a uri based on the node id, as is the case with Content graph articles. If a person has authored more than one Content graph article then all will be shown.

A note on authors ^
The authors data extracted from arXiv is not exactly as I would like. Ideally, a Content graph author object would have discrete metadata for things such as title, first name, last name and so on. Ideally, we could make use of an existing ontology such as schema.org or FOAF to model person information. Unfortunately, this amount of structure is not available in the arXiv library. In some cases, the author information even includes affiliation information, and even multiple versions, such as A. M. Gutin (who appears as A. M. Gutin (Dept of Chemistry Harvard University - Cambridge - MA) and A. M. Gutin (Harvard University - Department of Chemistry - Cambridge - MA), but not simply as A. M. Gutin). A further complication is that authors come from many different countries, in which the concepts of first (or given) name and last (or family) name may be conveyed differently from the way Western countries do it. For this set of articles I am not going to go further into the structure (or lack thereof) of author information, and simply live with it!
Choosing the Drupal Views to export information ^
Using the two basic content types in Drupal I created a range of views:
View url (RESTful export) | Notes |
web/api/articlelist | Produces a collection of JSON packages containing Content graph article title, node id and individual authors. |
web/api/authorslist | Produces a collection of urls and names of Content graph authors |
web/api/npu | Produces a collection of title, url and pdf url for Content graph articles |
web/pdf-urls (page, not RESTful) | Produces a simple list of all pdf urls. |
|
|
In later articles I will show how an external application can send RESTful queries to Drupal in order to retrieve these collections of information. The JSON data can be parsed using a variety of tools.
Recap ^
So let’s review where we are. I have defined some content types, for Content graph articles and Content graph authors. Each content type has been populated using the arXiv open data library, giving just over 800 Content graph article content objects and just over 1000 Content author content objects. I have built a set of Drupal Views that will allow me to extract selected information from the content management system for use in an external application.
Linking Content graph article and Content graph author information ^
My particular interest is getting Content graph articles linked to Content graph authors. This is accomplished by combining the RESTful outputs of two Drupal Views; that of the articlelist View combined with that of the authorslist View. The articlelist View gives us the Content graph article URI and linked author name. The authorslist View gives us the the Content graph author URI and author name. What we need, ultimately, is the respective URIs of article and author. So more processing is going to be needed; we need to find matching author names between these outputs. Here is an early middleware application that matches them up. I will cover this in much more detail in Part 4.

In this application, I retrieved both Views from Drupal, and then ran a comparison of author names from the two Views. Where I had a match I could infer a relation between a Content graph article uri and a Content graph author uri. This is not a perfect comparison, because authors can appear in different representations and my matching routine is far from intelligent. As in other cases, though, I had to be pragmatic, and to live with the few edge cases being missed. In Part 4 you will see exactly how I build the Content graph article to Content graph author relations and add them to the content graph.
Early form of the information model ^
It's worth mentioning that in the course of creating this content I have gone some way towards defining an information model for the content graph. There are two classes – Content graph article and Content graph author – and these classes have some initial metadata and relations. In later articles I will flesh the information model out. For now, here is a quick view of how the model might develop.

End of Part 2 ^
That brings me to the end of this second article. In the next part I’m going to cover taxonomy design and how we can build a collection of useful concepts that will have semantic links to content objects.
One more thing. From this point on, I'm going to refer to Content graph articles as Content graph items. The reason for this is that while it might make sense to use the word article when working in Drupal, once I move this information out to a content graph it would be more accurate to generalise the term to item, particularly since there may be other types of item than just articles.
Acknowledgements ^
I would like to thank Cornell University for making the arXiv library (https://arxiv.org) available as a free distribution service and an open-access archive for nearly 2.4 million scholarly articles.
I am grateful to Semantic Web Company for providing me with a cloud instance of PoolParty and excellent support. I am also grateful to Ontotext for creating a freeware version of GraphDB which has been very useful in building the content graph.
Finally, I would like to thank Sharon Hemming for her invaluable work in carrying out content management, taxonomy management, review and editing tasks in the development of this series of articles. Sharon works as a freelancer, providing content management, web design, software testing and project management services.