
A web content graph, part seven: GraphDB APIs
Across the first six articles I covered the use of information components representing structured content, taxonomies and graph databases to hold the relevant information (and only that information - separation of concerns, remember). I also showed how it is possible to build sophisticated interchanges of information between these components using application programming interfaces (APIs).
However, I left out one significant aspect; using the graph database API to manage the information. I'm using GraphDB in this set of articles; it has a good set of API methods that help to populate and explore the content graph. That is the subject of this article.
- Guiding principles for content graphs
- Content design for content graphs
- Taxonomy design for content graphs
- Middleware design for linking information
- Information model design for content graphs
- Using a graph database to tie everything together
- Managing a graph database using the api (this article)
In this article
Current status of the content graph ^
In part six I described how I could take an N-triples file (containing the triples data needed to build the content graph) and import it directly into the graph database. I used the middleware program to create the relevant triples data that underpin the content graph and then to write these triples out to a file (in N-triples format). Then I moved it to the GraphDB server file system and then into GraphDB using its import tools.
In practice, I really would like to send information across the network from my middleware program to GraphDB, rather than saving the triples out to a file and then importing that file. For that I need to use an api.
You can get to the api documentation at this url in your GraphDB installation:
http(s)://[server]/webapi
Or for a more comprehensive coverage go to the main GraphDB documentation section for the APIs:
https://graphdb.ontotext.com/documentation/10.8/clients-and-apis.html
I found that the local documentation was perfectly detailed enough, and had the additional benefit of having interactive tools to "Try it out"; very useful if you want to get all of the configuration right before writing code.
Introducing the REST APIs in GraphDB ^
Actually, Ontotext (the makers of GraphDB) provides access to two REST APIs; the GraphDB API and the RDF4J API. I'll describe both of these in this article. As a spoiler, however, I ended up using the RDF4J API for sending data from my middleware program to GraphDB, as I couldn't see a useful method to do what I needed in the GraphDB API.
Using the GraphDB API ^
The API documentation page, as mentioned above, both describes the API methods and allows you to run them interactively. This proved useful in working out how to configure the communications from Xojo to GraphDB.
On loading the page it shows a list of the available methods.
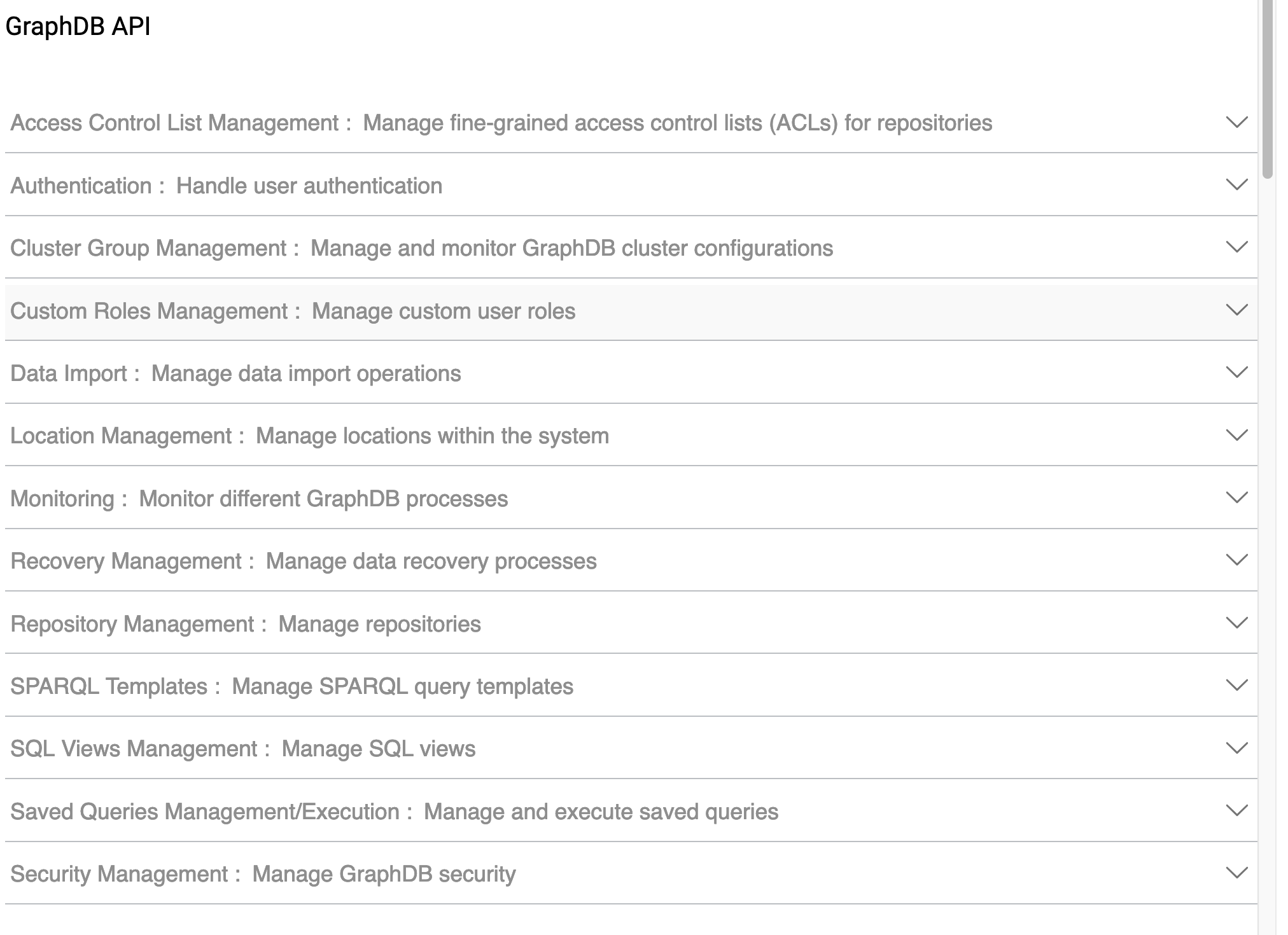
Clicking on an item in the list opens it up to show how it is configured. There may be several layers of configuration. The initial user interface for the authentication method is shown below (there is more, but I'm just showing the first part of the page).
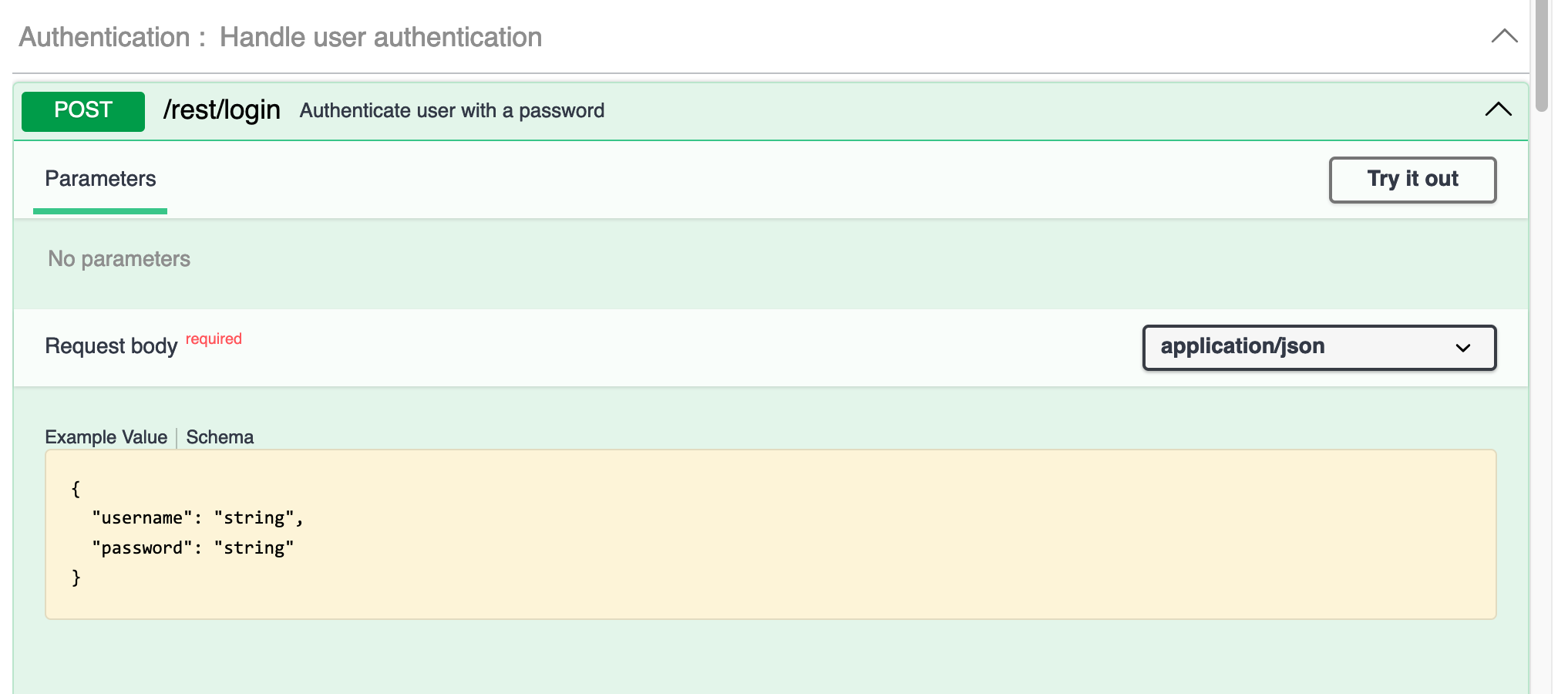
Clicking the Try it out button makes the form editable.
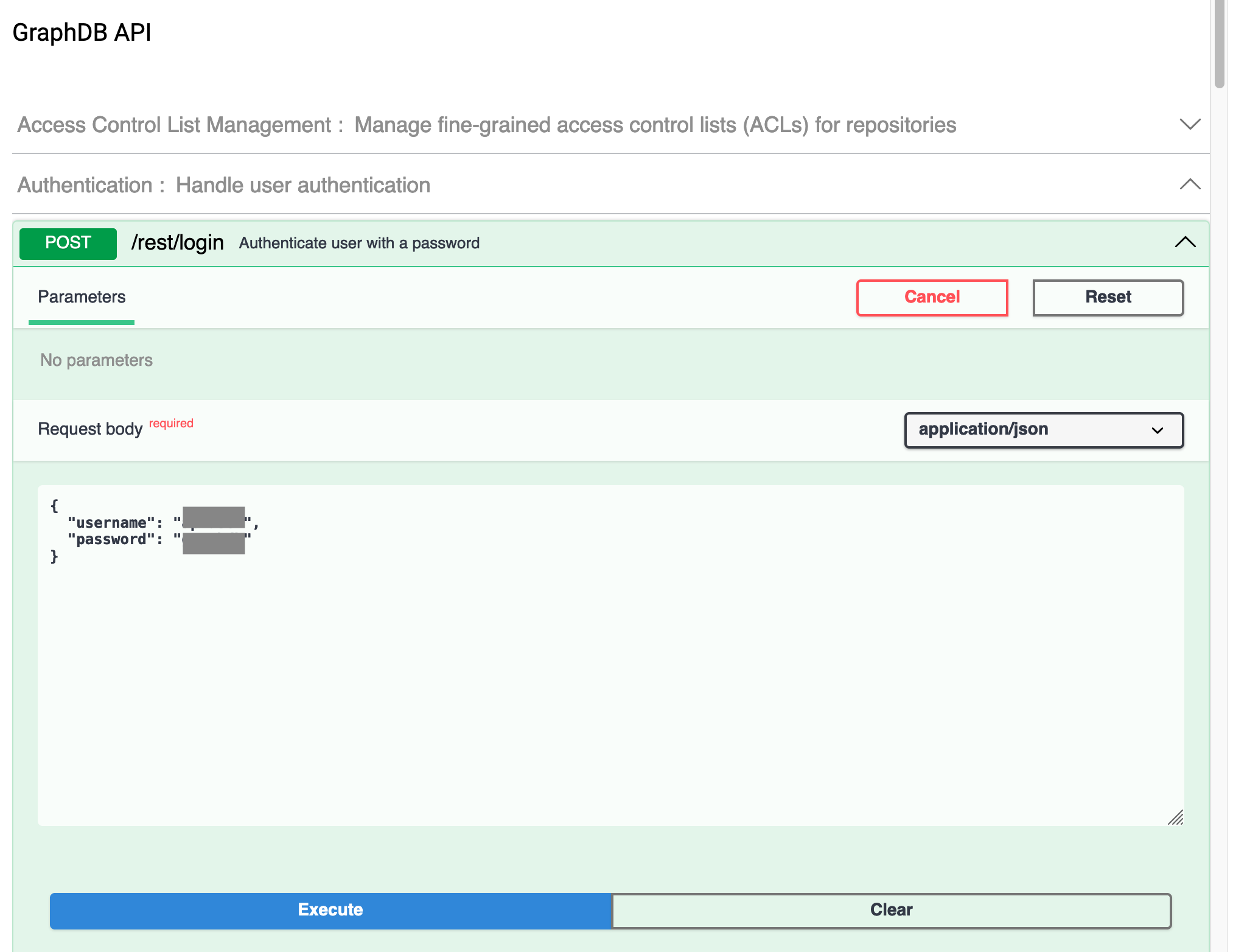
Note that I have greyed out the actual username and password. Clicking the Execute button runs the method and provides a fair amount of information. I've just included the first part here.
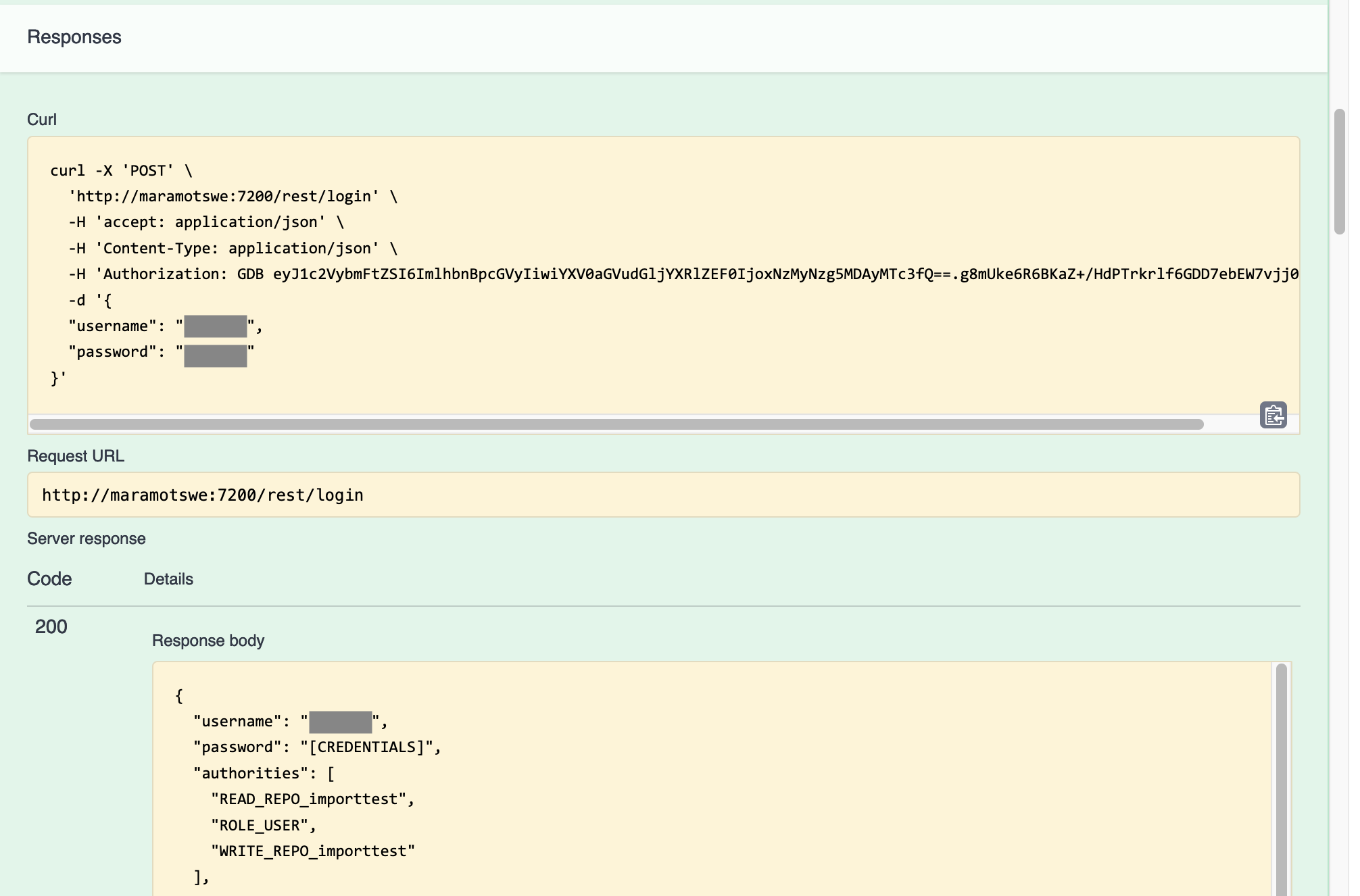
This is useful in setting out the requirements for running the method, all of which will be useful when moving over to Xojo. Note that the authorization header uses GDB type credentials, but as it turns out Basic authentication works just as well.
So if I wanted to try this in Xojo, I know how the request headers need to look, and the content that I need to send and expect to have returned.
However, having looked through the different methods available, I realised that there was no method for doing a remote update of a graph. There are data import methods, but these rely on a file being present in the server file system. Since I needed to set up communication between the middleware (which could be running anywhere, such as on my Mac) and the GraphDB server (which is on a Linux box), I turned to the second API available in GraphDB; the RDF4J API.
Using the RDF4J API ^
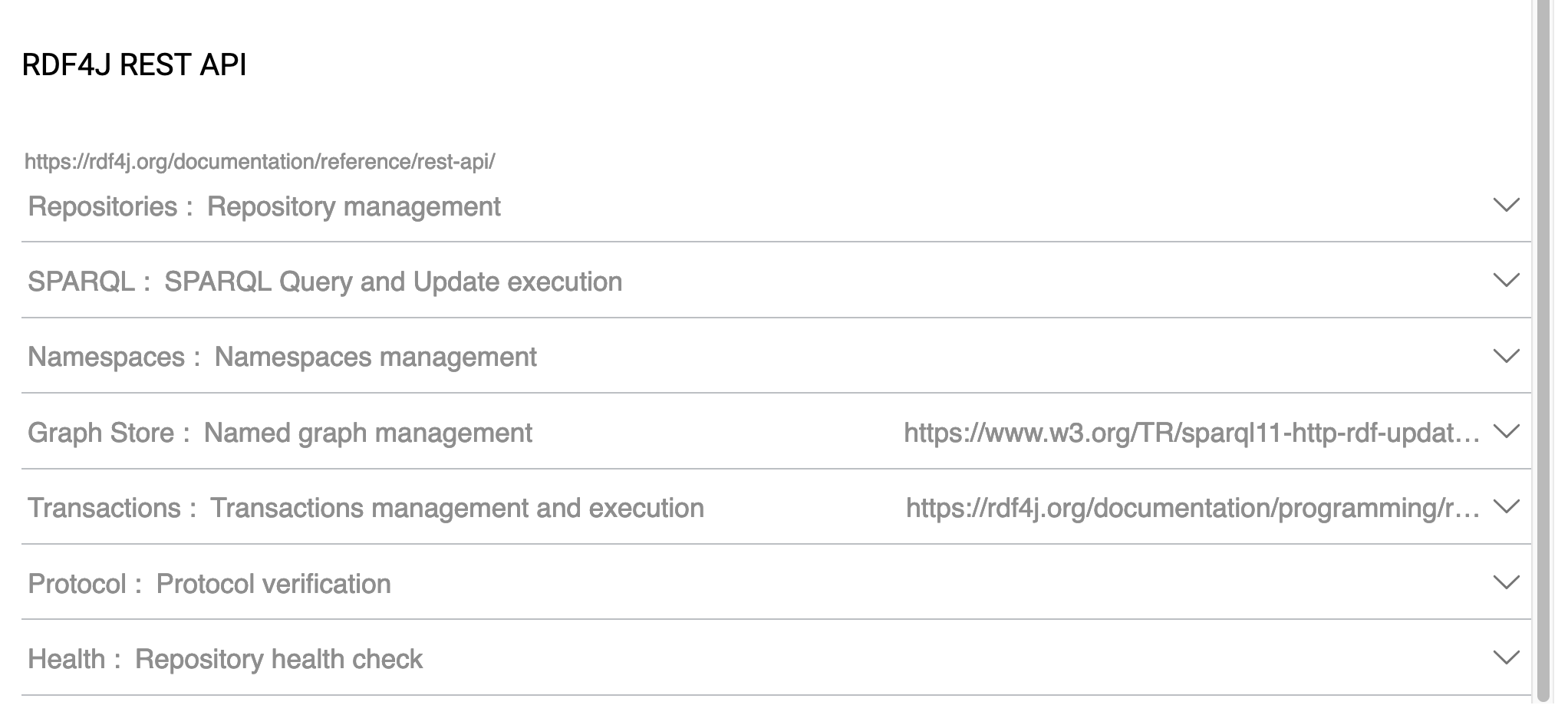
It turns out that this API does just what I want. Unfortunately, though very powerful, the GraphDB API did not offer the ability to update the graph with a stream of data rather than a file in the server file system. I needed to use a stream of data because the middleware program is run remotely and would not have access to the server file system.
The method that I need to use is one that allows me to create or update triples (or "statements" in GraphDB language) directly. This method is actually called statements (see /webapi in the context of a GraphDB installation). The method signature looks like this:
http(s)://[server]/repositories/{repositoryID}/statementsThis method sits under the Repository management section of the API documentation.
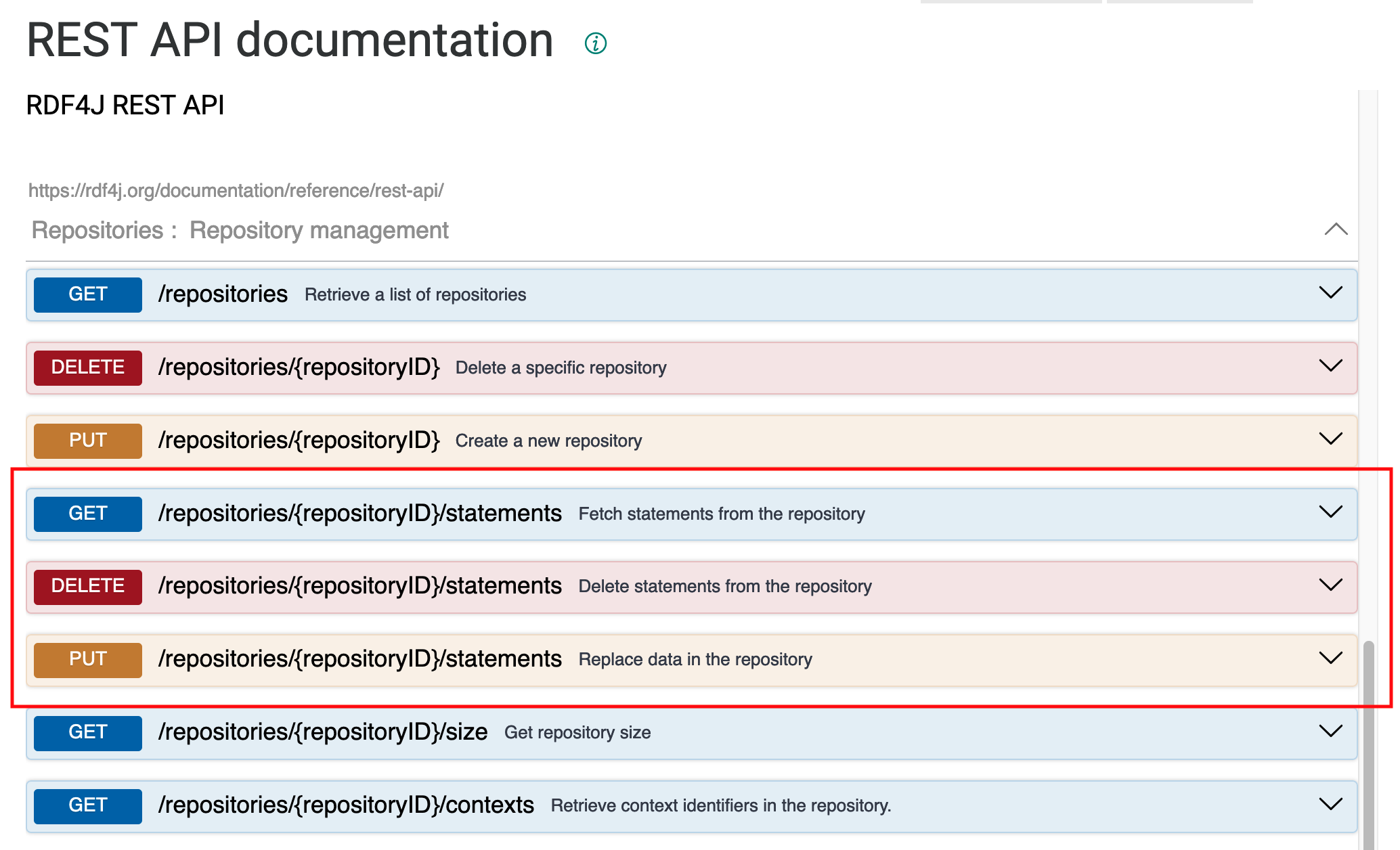
It can be used with GET, PUT and DELETE RESTful verbs in order to manage data in the graph. For the current purpose, I want to be able to use the triples that I create in the middleware program and then send them directly to GraphDB. So I need to use the PUT verb.
This section of the documentation is quite complex, and the various drop-down menus and options have a steep learning curve. However, it all actually works quite well once you have worked it out. The initial state of the documentation page looks like this:
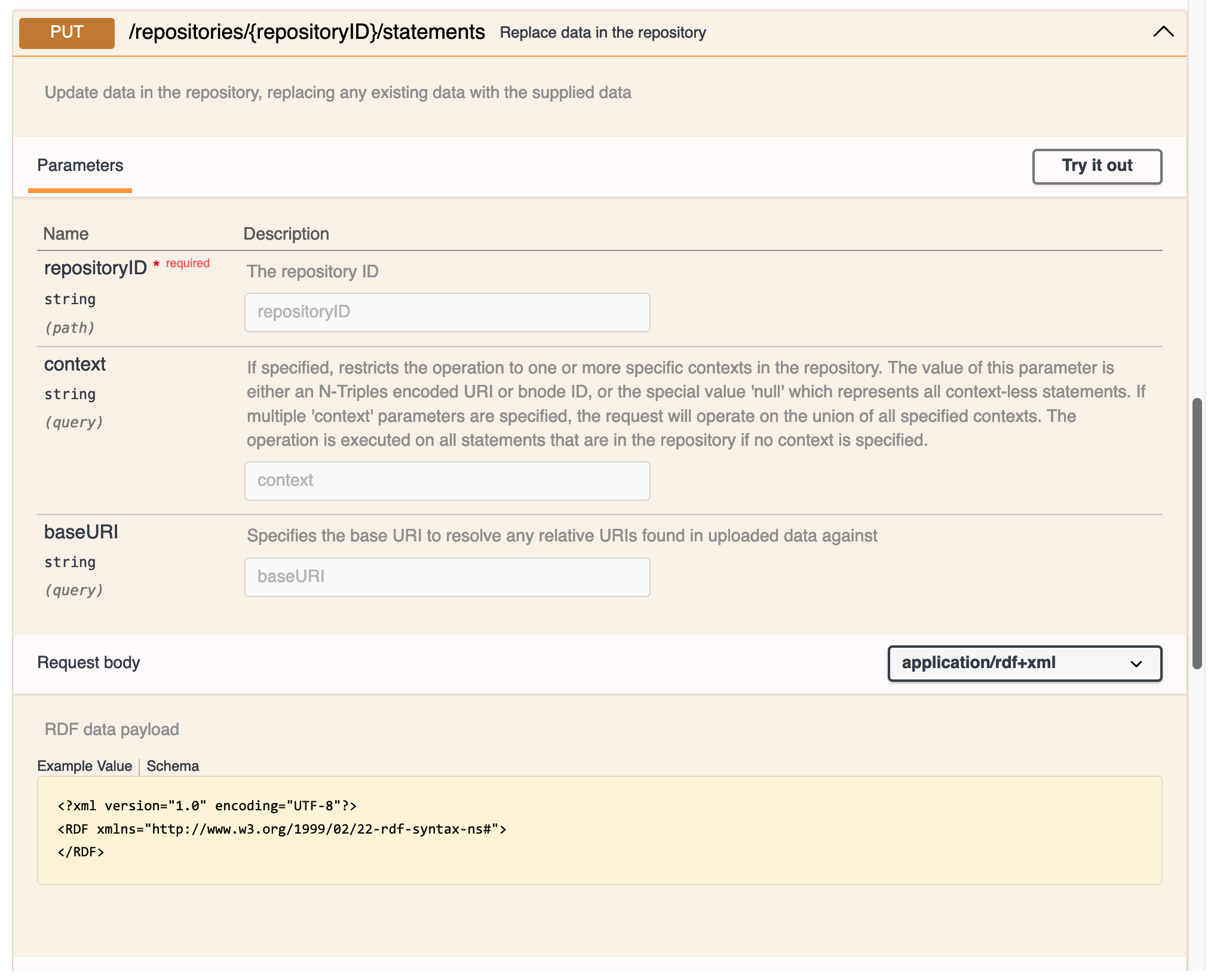
I could use the Try it out button to add the appropriate parameters and then run the method. To test this out initially, I created a new blank repository in my GraphDB installation called importtest. This initially has no data of course.

So then I returned to the documentation page and populated the interactive form so that it looked like this:
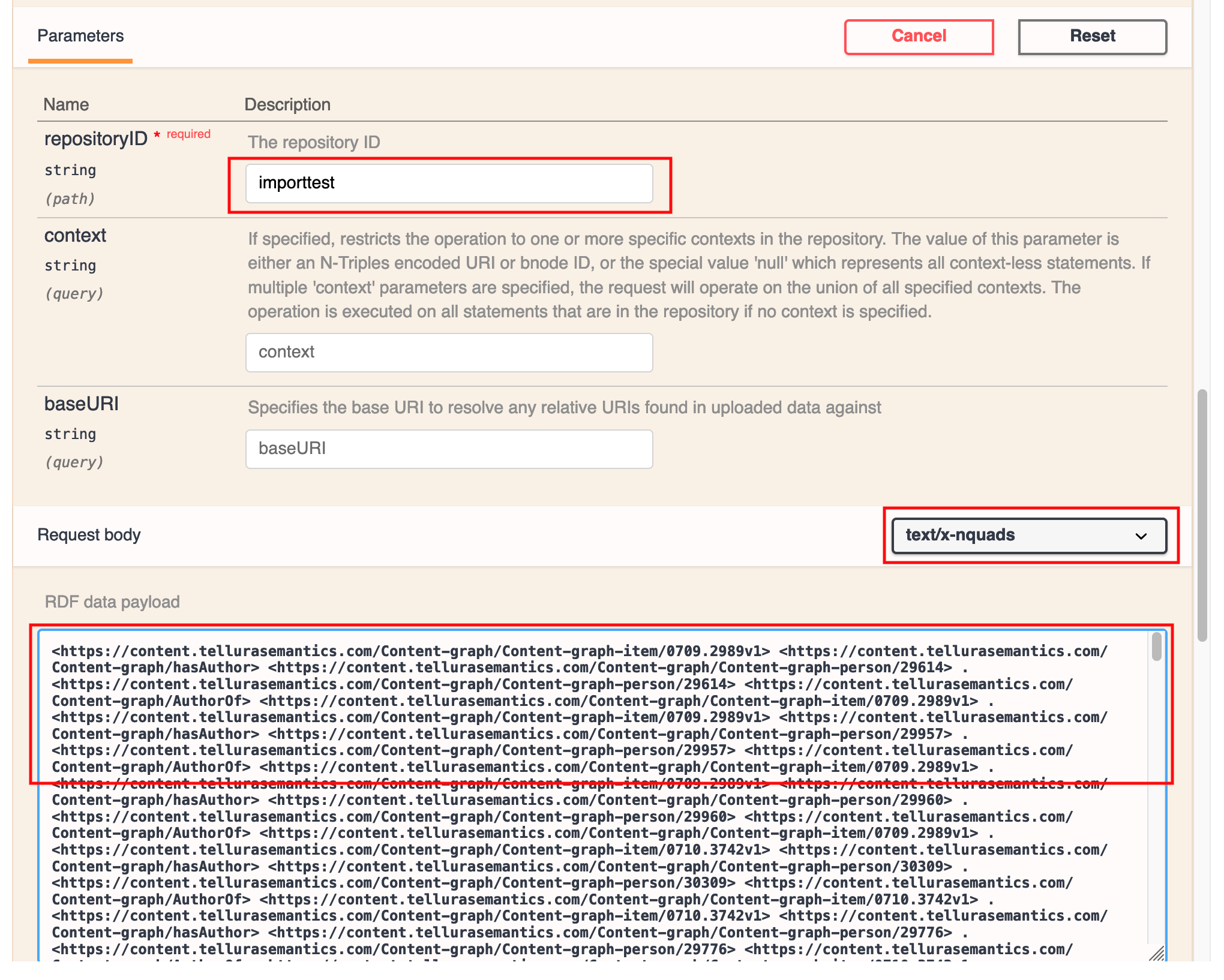
I added the repository ID (importtest) at the top, left the context and baseURI blank and pasted in the set of N-triples that I had previously imported as a file (see article 6 for more on this). The only other setting that I needed to be concerned about was the dropdown menu for the data type. I really wanted to use text/n-triples, but that option wasn't in the list. It turns out that n-quads worked in any case.
Once done, I used the Execute button to send the request to the server. This is the result:
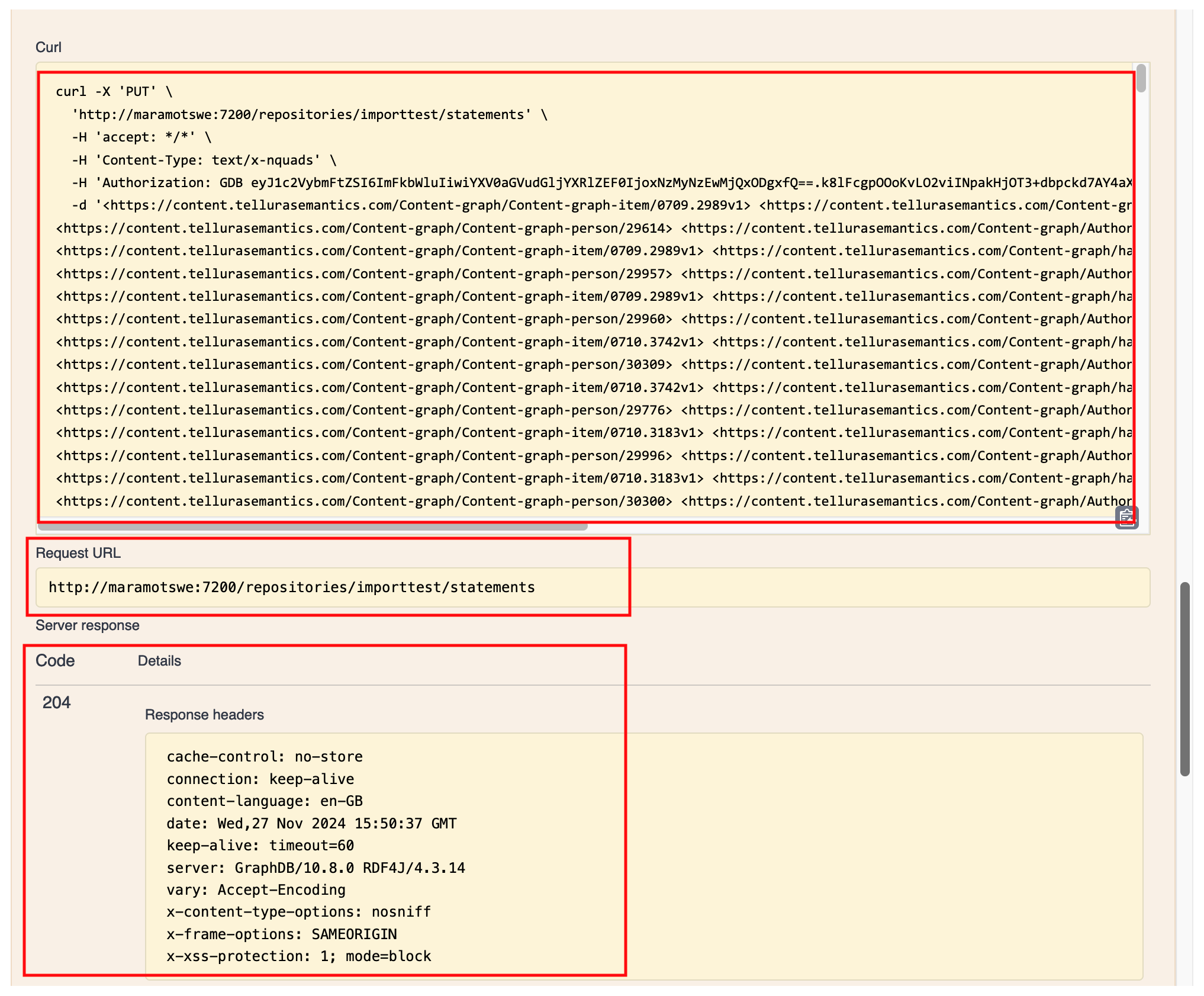
At the top you can see the curl request data (this interactive documentation uses curl for running the examples) and the request URL. Crucially, below this is the response, including the http code 204 (which means The data was successfully updated).
Going back to the GraphDB repository and the default graph, I could see that it was no longer empty:
OK, so that demonstrates that this method can be used to do updating of a repository. I now needed to repeat the process using my middleware program.
You will recall from article 6 that in the middleware program I populated a listbox with all of the triples that I needed to build the graph. Back then I saved the triples out to a file, which I then moved to the GraphDB server file system and imported to GraphDB using the interactive import tool. The next step is to gather up the information that I have used to populate the listbox, and to send it off to GraphDB with the statements method. It turns out to be quite straightforward to do this in Xojo.
In order to prepare for sending the statements, I emptied the default graph in GraphDB.
Now, in Xojo I created a new method called sendStatementsToGraphDB (verbose as ever). Here is the code:
// This method takes the current set of triples and uses the RDF4J api to write the triples into the default graph
// Note that the Content-Type GraphDB expects is text/x-nquads, but triples work just as well
// Set up variables
dim graphDBServerURL As String
dim graphDBUsername As String
dim graphDBPassword As String
dim graphDBMethod As String
dim requestURI As String
dim statementTriples As string
graphDBServerURL = txtGraphDBURL.Text
graphDBUsername = txtGraphDBUsername.Text
graphDBPassword = txtGraphDBPassword.Text
graphDBMethod = "PUT"
// get the listbox data into a string
for x as integer = 0 to lstOutputTriples.RowCount - 1
statementTriples = statementTriples + lstOutputTriples.CellTextAt(x,0) + EndOfLine.CRLF
next
// Send the triples to GraphDB
// the method is PUT, with the url http://maramotswe:7200/repositories/importtest/statements . Content type is text/nquads
ucGraphDB.ClearRequestHeaders
ucGraphDB.RequestHeader ("Authorization") = "Basic " + EncodeBase64(txtGraphDBUsername.Text + ":" + txtGraphDBPassword.Text)
ucGraphDB.RequestHeader ("Content-Type") = "text/x-nquads"
requestURI = "http://maramotswe:7200/repositories/importtest/statements"
ucGraphDB.SetRequestContent(statementTriples, "text/x-nquads")
ucGraphDB.Send("PUT", requestURI, 60)
// control moves to ucGraphDB.ContentReceived
The method first reads the listbox data into a string that will form the request content. Next, the request headers are populated with authorization information and a Content type of "text/x-nquads" (to reiterate, my data is n-triples but GraphDB doesn't provide this as an option so I used n-quads, and it worked fine). Finally I used the Send method (not SendSync this time) to send off the request. I did this because I wanted to capture the response code and any error messages, and in Xojo it is only possible to do this using Send.
Here is the UI for the final state of the middleware program.
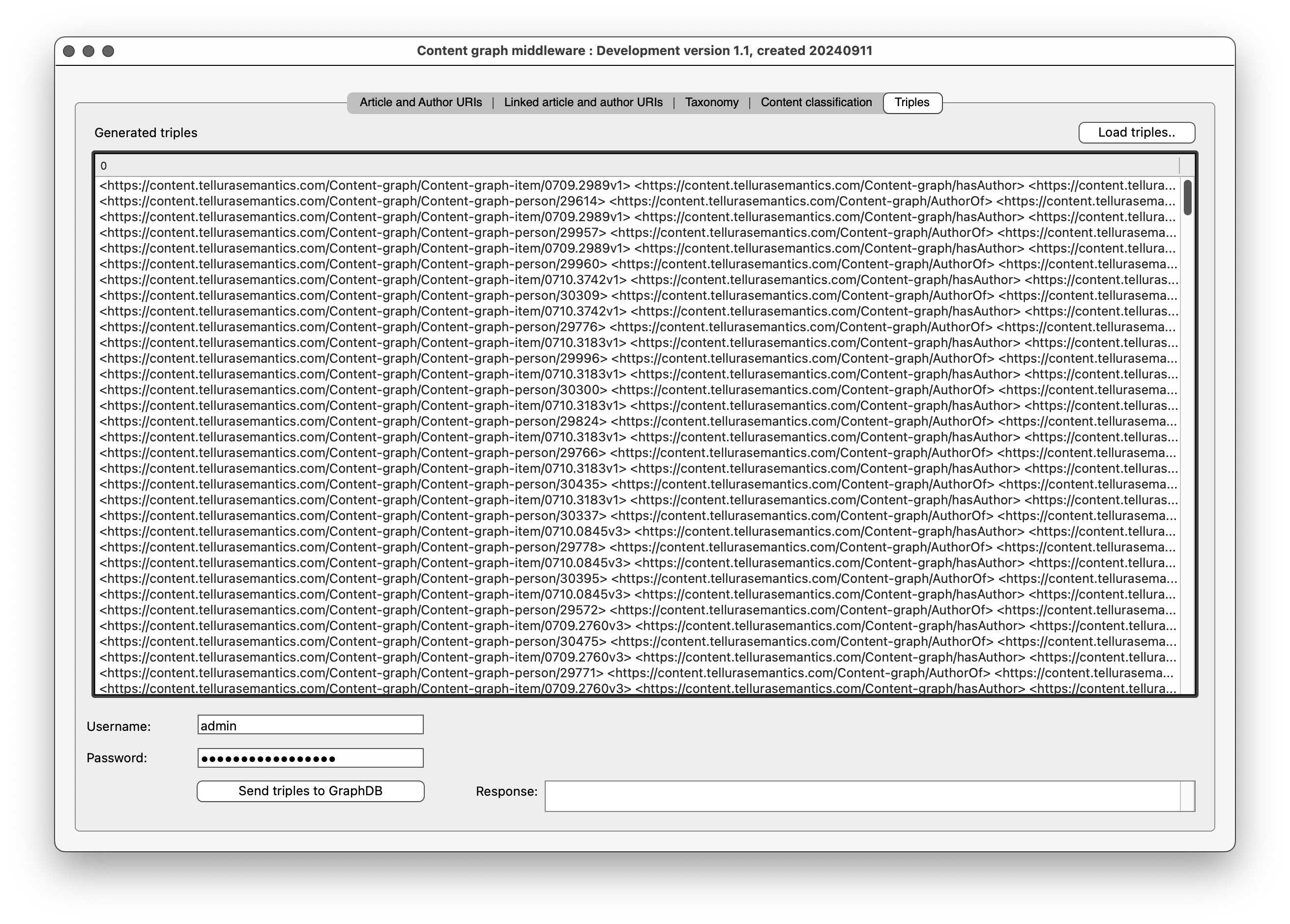
Clicking the Send button uses the urlConnection Send method to pass the request to GraphDB. I captured the response in the textbox at bottom right:

The response code is 204, which confirms a successful update in GraphDB. And when I return to GraphDB I see that the default graph is now populated.
Summary ^
This brings me to the end of article seven. This completes the end-to-end process of:
- Building a content repository using Drupal.
- Aligning content and author information using the Drupal RESTful API.
- Building a tagging taxonomy using PoolParty.
- Aligning the content objects with matching taxonomy concepts using PoolParty APIs.
- Creating triples to capture all of the above facts.
- Writing triples as a content graph to a GraphDB graph database.
- Visualising graph information with dynamic and explorable image tools.
Finally, I ought to stress again that although I've covered some fairly complex topics across these seven articles, the underlying ideas are really quite accessible. Remember, I did this and I am not a professional software developer. The key to all of this working was the fact that the different components - Drupal, PoolParty, GraphDB and Xojo - all provided very usable APIs that made it easy to build inter-application communications.
OK, if you have made it this far, I hope that you have found it useful and that it may inspire you to try these ideas out to build your own content graph. Please feel free to get in touch if you think Tellura can help you in your graph projects.