
Introducing the Content Graph Explorer
Note: this is an old article (December 2020). I have kept it here as it's all still true, but the work has been superseded by the new series of articles on building a content graph (September 2024).
In this article I'm introducing our new product; the Content Graph Explorer (CGE). If you haven't yet read the article Building a content graph you might like to take a look at it first, to explore some of the background ideas.
I've used the term Content Graph to describe a knowledge graph based on content objects, taxonomy concepts and semantic triples. A content graph contains a collection of content objects and taxonomy concepts linked together using a semantic information model. Each link is stored as a triple, which is essentially a nugget of knowledge consisting of a thing, another thing and a meaningful link between the two. The graph, as a collection of triples, is stored in a triple store, and thus available for exploration and discovery using semantic technologies.
If none of this makes immediate sense, you are not alone. The ideas are different from classical information storage, and a million miles away from traditional searching. The disconnect between the commonly-expressed desire for businesses to connect up all of their relevant information assets, and the almost-impossibility of achieving that goal with yesterday's tools is something that we grapple with daily with clients, and it is what has driven the development of the Content Graph Explorer.
The Content Graph Explorer is, as a result, partly an awareness raising and/or educational tool. At Tellura we use it to show exactly how a body of content can be linked to a set of taxonomy concepts, with the results stored in a graph database and then made available for search and exploration. More to the point though, we use it to explain why it makes sense, and what business benefits come out of it.
The most conventional way to think of the Content Graph Explorer is as a go-between. It is a web application that can be located anywhere (on your premises or in the cloud) and that knows how to communicate with your content management system, your taxonomy management system and your graph database management system. Here's how the overall architecture looks.
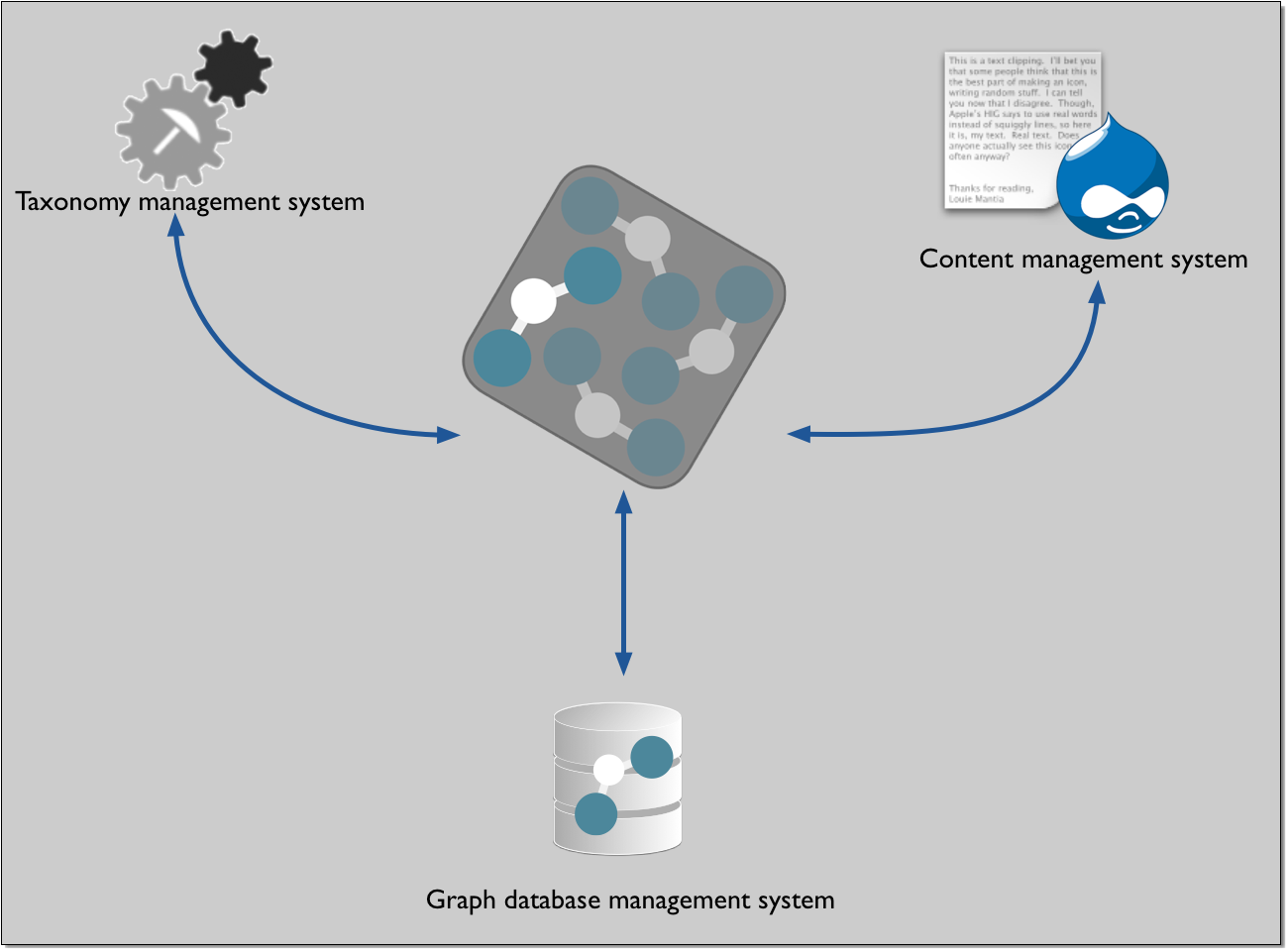
There is a lot going on here, so I'm going to break it down into chunks.
The first part to look at is the content management system (CMS). This is where you store items of content. Each item of content (or content object, if it is properly structured) will have some sort of payload; that is, the core content. For example, the article you're reading now is held as a content object in a Drupal CMS, and the words and images that you are looking at now are part of the content payload. In addition to the content payload, the content object will have metadata; this metadata mostly contains things such as the title, the author, the publication date/time and so on, and a special piece of structural metadata is the identifier; in the semantic world this identifier is a Uniform Resource Identifier (URI). Another special type of metadata is the taxonomy concepts that are used to classify this content - the aboutness of the content. In a conventional CMS this classification may use an internal taxonomy, but in the semantic world this classification is handled in an external taxonomy management system.
So let's move to the taxonomy management system. This is where you manage the concepts. If you use a structured taxonomy management system such as PoolParty these concepts all have URIs as unique identifiers, just like our content items. So in practical terms, the classification of a content item will be a link connecting the URI of a content object and the URIs of one or more taxonomy concepts. Our Content Graph Explorer uses the APIs of Drupal and PoolParty to match up a content object to the taxonomy concepts. Each of the matches - this content URI has a match with a concept URI - is captured in the form of a semantic triple. The process of linking a content object to a taxonomy concept is what I am calling a classification event. Any content item could be about a number of topics, so it may have many classification events. And each such event is captured as a semantic triple.
As you will know from reading other resources about the Semantic Web, a semantic triple has a subject (the content URI in this case), an object (the concept URI here) and a predicate. The predicate is a linking verb; it defines the kind of relationship between the content and the concept. In the Content Graph Explorer we have built an information model that allows us to define the predicate that we will use for each content classification event that we create. Without going into too much detail in this short article, this model allows us to make use of the taxonomy hierarchy structure in order to provide a variety of useful meaningful predicates. For example, if we have a collection of taxonomy concepts in a concept scheme called Country, then we can use a predicate like hasCountry to link a content item that is relevant for the US market to form a triple like this:
<https://content.tellurasemantics.com/US-market-review-201803191314> ts:hasCountry <https://tellura.poolparty.biz/BusinessTaxonomy/United-States>
So our Content Graph Explorer enables us to build up a set of semantic triples like this, each one linking a content object to a taxonomy concept using a meaningful relationship. Each of these three components is a URI that enables us to get back to the original thing.
There's another component in this architecture that I haven't yet described. This is the triple store (or graph database management system). And as the name suggests, this is where we store the triples that the classification event has produced. We need to store this somewhere, and although we could work out a way to store such things in the CMS or the taxonomy management system, there is no great benefit in doing so. Putting the triple into a triple store, along with every other triple that we create, means that we have a rich data store that is explorable. We can ask questions such as "What content objects are intended for the US market?", "What content items are country-focused?", "What other content is classified in a similar fashion to this content object?" and so on. Furthermore, if we store triples from other information services in the same triple store, we can link information in one to information in the other. Since a subject in one triple can be the object in another, we can start to build up extended networks of connected information. Here is an example from a collection of legal content, showing a graphical UI that we have developed in order to be able to navigate through a content graph. The graphical image is built up by creating queries that retrieve triples from the graph database, and then transform them into a visually-navigable format.

The blue circles represent content objects, while the orange circles show the concepts used to classify the content. You can see that, starting from the document entitled "Employer did not have[...]" we can see a number of concepts that the content is about. Moving the focus to one of those concepts (labelled "Court of Appeal") we can see that this concept has also been used to classify a number of other content objects. And if I were to navigate through to one of those objects, the visual graph would elaborate to include its classifications. This process allows us to navigate across the content graph, bringing out new insights and connections.
We can go further. Suppose we also used our taxonomy management system to classify other information objects - such as digital media in a digital asset management system (DAM). We could drop those triples into the same triple store, and now explore relationships between content objects and rich media assets. Suppose we built up a graph of people and their interests, and included those triples. We could then explore from content to authors, to their interests, to other people, to other content, and onwards.
Extracting these relationships out of the core CMS (or DAM) systems and moving them into a triple store clearly confers advantages in terms of building a knowledge network, but there is another, more everyday benefit. The architecture diagram above shows that we are storing the right things in the right places; it's often called separation of concerns in geek-speak. But because we have the content objects and nothing else in the content management system, there is no dependency between the CMS and the taxonomy management system. If - sorry, when the organisation decides to migrate to another CMS, the classification will not be lost (as it so often is with traditional tagging technologies). It won't be lost because it won't be touched - it's safely captured in the triple store. So implementing separation of concerns reduces your dependencies and makes it easier for you to choose the best system for the particular job you need to do.
We have successfully implemented Content Graph Explorer technologies in several environments. Since it is effectively a connector linking systems via their APIs, the Content Graph Explorer can be readily adapted to work with other content management and information management systems. If this is something that would benefit your business, please get in touch - we'd love to talk with you about how we can help to make it happen!