
Why things work better than strings
Human beings are natural organisers; we spend our entire lives classifying things, grouping and ordering things and comparing and contrasting things with other things. It's probably a trait that helped us survive and evolve - being able to distinguish one type of four-legged furry creature (a sheep - eat it) from another four-legged furry creature (a lion - run away from it) must have been a useful survival skill. The process through which we organise the things in our world is very much about building taxonomies, even when we don't recognize that process. Perhaps it's the very fact that it is so deeply embedded in the way we think that makes it so difficult to spell out the basic rules when it comes to taxonomies of information. It's a shame, because it isn't that complex. So here goes; I'm going to talk a bit about taxonomies here and try to give the topic some language that helps spell out some of those rules. Later on I'm going to move out into the broader world of ontologies, but that's not the main focus, so let's start closer to home.
Simply put, a taxonomy is a collection of things that we can arrange into a logical structure - a structure that helps us to explore the relationships between those things in a meaningful manner. The pet in your house may be a Yellow Labrador. That means it's a type of Labrador, but it's different from a Black Labrador. A Labrador is a breed of domesticated dog, but it's different from other breeds such as Border Terriers and Spaniels. A domesticated dog is a type of dog that is different from wolves, foxes and dingos, and a dog is a carnivore that's different from lions, tigers and cats. All of these things are mammals, and four-legged, and fur-bearing, and animals, and living things. We just built a taxonomy of living things that helps us to group, organise, compare and contrast those things. People often use a tree structure to illustrate the hierarchical nature of taxonomies.

Simple taxonomies can only give us so much information though. In the example above, although we can build a tree structure to hold these terms, they are just that; terms, or strings of text. The word Labrador only conveys meaning to us as a type of dog because we happen to know that this thing represents a dog, and not a place in eastern Canada. The taxonomy doesn't contain any useful information that unambiguously tells us that; we're reliant on inference, on knowledge in the world.
In the world of information management, taxonomies give us a good way to classify our content, by the process of tagging. Most content management systems have some sort of internal taxonomy, usually a collection of text-based lists. Tagging an individual item of content with different terms from that taxonomy is a way to help find collections of related content.
Here we have the same basic needs to organise and classify the things we work with. But by restricting ourselves to traditional term-based taxonomies we run the same risks of ambiguity; this content is tagged with the term Java; is this the Java that’s a place, or a programming language, or a variety of coffee? It’s hard to know, because the term we use has no other information than those four letters; J-a-v-a. And if we happen to have different content items tagged with the term Java, we can't even be sure that those content items are about the same Java.
However if, instead of relying on string-based terms for classification, we make use of modern notions such as semantic graph data, and modern standards and tools, we can give our information systems additional richness and capability and overcome that ambiguity. We can do this by extending our simple, pure text-based taxonomies - collections of strings - into concept-based taxonomies that are collections of things.
So what's the difference between a term (a string) and a concept (a thing)? A term called Bank account is just a string of characters. We can use that in a simple taxonomy to classify information (say, in a content management system), but it's risky. Someone else might create a term called Current account and use that to classify content. We would end up with two pieces of essentially similar content that have been classified with two different terms. At some point in the future we might decide to rename the term to Banking account, and new content would be classified differently from old.
This is where a concept comes in. A concept is an information object - an abstract package of information that encapsulates the idea that you want to convey. This is how we move from strings to things. Taking the term Bank account (a string) let's try to re-cast it as a concept (a thing).
- The phrase Bank account is just a label that we hang on the concept for humans to read.
- We give it an unique identifier (actually, a Uniform Resource Identifier or URI).
- There are other labels that we could apply to this concept, which can act as synonyms or other language labels: Current account, Bank Konto (German or de), Compte bancaire (French or fr), Conto bancario (Italian or it)
- We can describe meaningful relationships between this concept and other concepts: concepts with labels like Cheque account, Savings account, and so on.
- We can link this concept to similar or identical concepts in other information systems (say, to the DBpedia resource with the URI http://dbpedia.org/page/Bank_account) using a semantic link. You can start to think of this as an abstract information object, with a way to both identify and locate it (the URI) and a range of properties that allow humans and machines to read it and link it to other things. It's so much richer than just a string of characters.
But wait... that last description; a semantic link. What does that mean? It's actually at the heart of all of the benefits that accrue from moving from strings to things. A semantic link is a way of saying not only that one thing is related to another thing, but also how it's related. That final bullet point above might be written like this:
http://example.com/economy/bank-account skos:exactMatch http://dbpedia.org/page/Bank_account
This relationship can be expanded to say "the taxonomy concept that has the URI http://example.com/economy/bank-account has an exact match as defined by the SKOS ontology to the DBpedia resource identified by the URI http://dbpedia.org/page/Bank_account ".
In a taxonomy, the concepts are essentially members or individuals in a collection that conforms to a common structure. That structure is an ontology - specifically, the SKOS ontology.
Let's run over that in more detail. The taxonomy is not a design or a framework - it is a concrete collection describing real individuals, which have (at least) two things in common:
- They are all about the same kind of thing
- They all conform to the SKOS standard or ontology
Which is the natural point to start to talk about ontologies.
Taxonomies are not the same as ontologies
An ontology is, in a nutshell, a model, or a design, or a template, for structured information. At the very least it defines the things (or classes) and their relationships (or properties) to other things. Let's take as an example an ontology that describes human families. This ontology has a top-level class of Person, and a set of sub-classes (things that are all Persons):
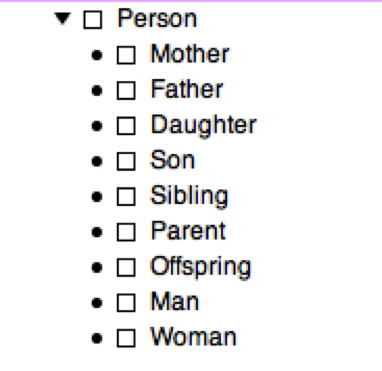
As well as being types of Person, we can say much more in the form of the relationships between classes. For example, a Son is a Person that has a hasParent relationship to another Person and also has a hasGender relationship to an individual called Male. We can say that a hasParent relationship has an inverse relationship of hasChild. We can build in rules that say that if a Person has a hasParent relationship to another Person, then that Person can't have the same relationship back to the first Person (in plain English, your father cannot also be your son). We can say that a hasSibling relationship is symmetrical, so that if a Person has a hasSibling relationship to another Person, the same relationship must exist in the other direction. We can say that a Person can have only one hasMother relationship (though a Person can have many hasChild relationships).
These are semantic relationships. They don't just describe two things that are related; they give meaning (what kind of relationship?) and dimension (how many? symmetrical?) to the relationship. Together, they build up a consistent model of part of the world of knowledge, and this in turn allows you to create knowledge networks.
Essentially, an ontology describes the classes of information object and the ways in which individuals will have to behave.
And there is the key distinction between an ontology and a taxonomy. An ontology needs only to define the structure and behaviour. It doesn't need to describe individuals. In the case above, we could create some concrete individuals that conform to the ontology (Ian is a Person. Alice is a Person. Ben is a Person. Ian hasChild Alice, so Alice hasParent Ian. Alice hasSibling Ben, so Ben hasSibling Alice. And so on). But the ontology stands on its own, without having to rely on individual members. A (SKOS) taxonomy by contrast is a set of individuals that conform to the structure and behaviour of the SKOS ontology. The SKOS ontology is the model or template, and the taxonomy is the concrete rendition. So if you create a taxonomy using a tool such as PoolParty, you might create a hierarchy like this:
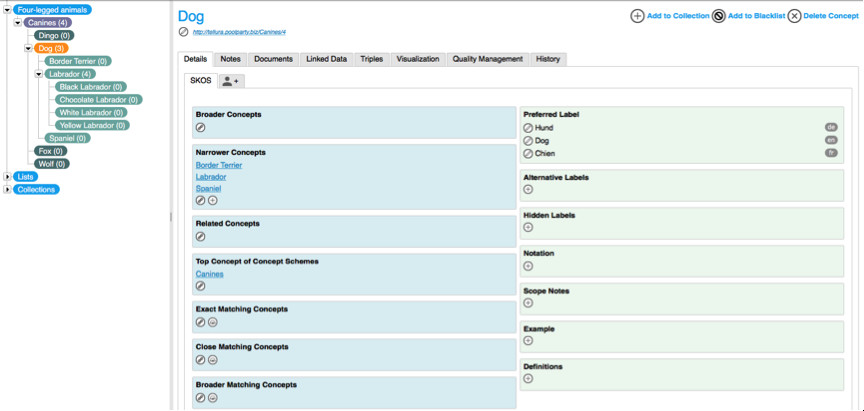
The concept of Dog is highlighted here. It has a URI (http://tellura.poolparty.biz/Canines/4). It has a broader concept (with the preferred label Canines) and a number of narrower concepts. It has Preferred labels of Dog (en), Hund (de) and Chien (fr). It might have other properties too, which are all captured as semantic triple statements conforming to the SKOS standard:
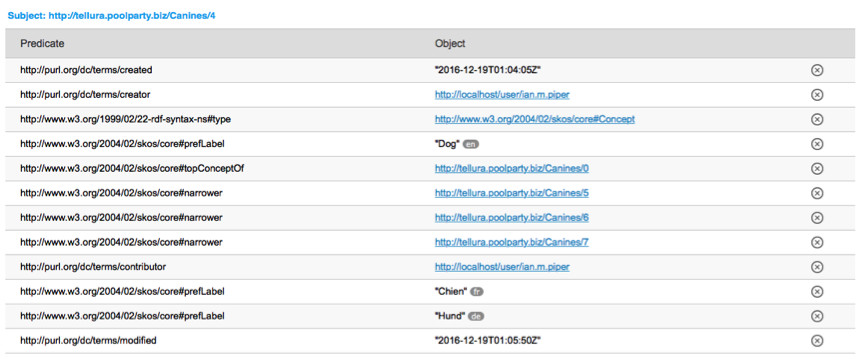
So a modern taxonomy is a collection of individuals that conform to the SKOS ontology. That conformance confers information richness and precision to the concepts described in the taxonomy, so that when they are used in classifying information we can use those classifications to build strong and meaningful networks of knowledge, in ways that traditional term-based taxonomies cannot. An ontology is a design or model for structured information, and may contain individuals.
Well, if you've stayed the course so far, thanks for taking the time to read this. I hope that I've managed to shine a light on why rich taxonomies of things work better than simple taxonomies of strings, how the richness of taxonomies are helping in the emergence of knowledge networks in organisations, and a little about how ontologies help us to understand structure and meaning in the design of our content.